first add
This commit is contained in:
commit
7bf77f5282
14
.obsidian/app.json
vendored
Normal file
14
.obsidian/app.json
vendored
Normal file
@ -0,0 +1,14 @@
|
||||
{
|
||||
"promptDelete": false,
|
||||
"pdfExportSettings": {
|
||||
"pageSize": "Letter",
|
||||
"landscape": false,
|
||||
"margin": "0",
|
||||
"downscalePercent": 100
|
||||
},
|
||||
"vimMode": true,
|
||||
"attachmentFolderPath": "attachments",
|
||||
"useMarkdownLinks": true,
|
||||
"newLinkFormat": "relative",
|
||||
"alwaysUpdateLinks": true
|
||||
}
|
||||
4
.obsidian/appearance.json
vendored
Normal file
4
.obsidian/appearance.json
vendored
Normal file
@ -0,0 +1,4 @@
|
||||
{
|
||||
"showRibbon": true,
|
||||
"translucency": true
|
||||
}
|
||||
3
.obsidian/backlink.json
vendored
Normal file
3
.obsidian/backlink.json
vendored
Normal file
@ -0,0 +1,3 @@
|
||||
{
|
||||
"backlinkInDocument": true
|
||||
}
|
||||
7
.obsidian/community-plugins.json
vendored
Normal file
7
.obsidian/community-plugins.json
vendored
Normal file
@ -0,0 +1,7 @@
|
||||
[
|
||||
"dataview",
|
||||
"obsidian-day-planner",
|
||||
"obsidian-importer",
|
||||
"obsidian-kanban",
|
||||
"obsidian-git"
|
||||
]
|
||||
31
.obsidian/core-plugins.json
vendored
Normal file
31
.obsidian/core-plugins.json
vendored
Normal file
@ -0,0 +1,31 @@
|
||||
{
|
||||
"file-explorer": true,
|
||||
"global-search": true,
|
||||
"switcher": true,
|
||||
"graph": true,
|
||||
"backlink": true,
|
||||
"canvas": true,
|
||||
"outgoing-link": true,
|
||||
"tag-pane": true,
|
||||
"properties": false,
|
||||
"page-preview": true,
|
||||
"daily-notes": true,
|
||||
"templates": true,
|
||||
"note-composer": true,
|
||||
"command-palette": true,
|
||||
"slash-command": false,
|
||||
"editor-status": true,
|
||||
"bookmarks": true,
|
||||
"markdown-importer": true,
|
||||
"zk-prefixer": false,
|
||||
"random-note": false,
|
||||
"outline": true,
|
||||
"word-count": true,
|
||||
"slides": false,
|
||||
"audio-recorder": false,
|
||||
"workspaces": false,
|
||||
"file-recovery": true,
|
||||
"publish": false,
|
||||
"sync": true,
|
||||
"webviewer": false
|
||||
}
|
||||
22
.obsidian/graph.json
vendored
Normal file
22
.obsidian/graph.json
vendored
Normal file
@ -0,0 +1,22 @@
|
||||
{
|
||||
"collapse-filter": true,
|
||||
"search": "",
|
||||
"showTags": false,
|
||||
"showAttachments": false,
|
||||
"hideUnresolved": false,
|
||||
"showOrphans": true,
|
||||
"collapse-color-groups": true,
|
||||
"colorGroups": [],
|
||||
"collapse-display": true,
|
||||
"showArrow": false,
|
||||
"textFadeMultiplier": 0,
|
||||
"nodeSizeMultiplier": 1,
|
||||
"lineSizeMultiplier": 1,
|
||||
"collapse-forces": true,
|
||||
"centerStrength": 0.518713248970312,
|
||||
"repelStrength": 10,
|
||||
"linkStrength": 1,
|
||||
"linkDistance": 250,
|
||||
"scale": 1.3486109551319057,
|
||||
"close": false
|
||||
}
|
||||
3
.obsidian/page-preview.json
vendored
Normal file
3
.obsidian/page-preview.json
vendored
Normal file
@ -0,0 +1,3 @@
|
||||
{
|
||||
"preview": true
|
||||
}
|
||||
20876
.obsidian/plugins/dataview/main.js
vendored
Normal file
20876
.obsidian/plugins/dataview/main.js
vendored
Normal file
File diff suppressed because one or more lines are too long
11
.obsidian/plugins/dataview/manifest.json
vendored
Normal file
11
.obsidian/plugins/dataview/manifest.json
vendored
Normal file
@ -0,0 +1,11 @@
|
||||
{
|
||||
"id": "dataview",
|
||||
"name": "Dataview",
|
||||
"version": "0.5.68",
|
||||
"minAppVersion": "0.13.11",
|
||||
"description": "Complex data views for the data-obsessed.",
|
||||
"author": "Michael Brenan <blacksmithgu@gmail.com>",
|
||||
"authorUrl": "https://github.com/blacksmithgu",
|
||||
"helpUrl": "https://blacksmithgu.github.io/obsidian-dataview/",
|
||||
"isDesktopOnly": false
|
||||
}
|
||||
141
.obsidian/plugins/dataview/styles.css
vendored
Normal file
141
.obsidian/plugins/dataview/styles.css
vendored
Normal file
@ -0,0 +1,141 @@
|
||||
.block-language-dataview {
|
||||
overflow-y: auto;
|
||||
}
|
||||
|
||||
/*****************/
|
||||
/** Table Views **/
|
||||
/*****************/
|
||||
|
||||
/* List View Default Styling; rendered internally as a table. */
|
||||
.table-view-table {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.table-view-table > thead > tr, .table-view-table > tbody > tr {
|
||||
margin-top: 1em;
|
||||
margin-bottom: 1em;
|
||||
text-align: left;
|
||||
}
|
||||
|
||||
.table-view-table > tbody > tr:hover {
|
||||
background-color: var(--table-row-background-hover);
|
||||
}
|
||||
|
||||
.table-view-table > thead > tr > th {
|
||||
font-weight: 700;
|
||||
font-size: larger;
|
||||
border-top: none;
|
||||
border-left: none;
|
||||
border-right: none;
|
||||
border-bottom: solid;
|
||||
|
||||
max-width: 100%;
|
||||
}
|
||||
|
||||
.table-view-table > tbody > tr > td {
|
||||
text-align: left;
|
||||
border: none;
|
||||
font-weight: 400;
|
||||
max-width: 100%;
|
||||
}
|
||||
|
||||
.table-view-table ul, .table-view-table ol {
|
||||
margin-block-start: 0.2em !important;
|
||||
margin-block-end: 0.2em !important;
|
||||
}
|
||||
|
||||
/** Rendered value styling for any view. */
|
||||
.dataview-result-list-root-ul {
|
||||
padding: 0em !important;
|
||||
margin: 0em !important;
|
||||
}
|
||||
|
||||
.dataview-result-list-ul {
|
||||
margin-block-start: 0.2em !important;
|
||||
margin-block-end: 0.2em !important;
|
||||
}
|
||||
|
||||
/** Generic grouping styling. */
|
||||
.dataview.result-group {
|
||||
padding-left: 8px;
|
||||
}
|
||||
|
||||
/*******************/
|
||||
/** Inline Fields **/
|
||||
/*******************/
|
||||
|
||||
.dataview.inline-field-key {
|
||||
padding-left: 8px;
|
||||
padding-right: 8px;
|
||||
font-family: var(--font-monospace);
|
||||
background-color: var(--background-primary-alt);
|
||||
color: var(--nav-item-color-selected);
|
||||
}
|
||||
|
||||
.dataview.inline-field-value {
|
||||
padding-left: 8px;
|
||||
padding-right: 8px;
|
||||
font-family: var(--font-monospace);
|
||||
background-color: var(--background-secondary-alt);
|
||||
color: var(--nav-item-color-selected);
|
||||
}
|
||||
|
||||
.dataview.inline-field-standalone-value {
|
||||
padding-left: 8px;
|
||||
padding-right: 8px;
|
||||
font-family: var(--font-monospace);
|
||||
background-color: var(--background-secondary-alt);
|
||||
color: var(--nav-item-color-selected);
|
||||
}
|
||||
|
||||
/***************/
|
||||
/** Task View **/
|
||||
/***************/
|
||||
|
||||
.dataview.task-list-item, .dataview.task-list-basic-item {
|
||||
margin-top: 3px;
|
||||
margin-bottom: 3px;
|
||||
transition: 0.4s;
|
||||
}
|
||||
|
||||
.dataview.task-list-item:hover, .dataview.task-list-basic-item:hover {
|
||||
background-color: var(--text-selection);
|
||||
box-shadow: -40px 0 0 var(--text-selection);
|
||||
cursor: pointer;
|
||||
}
|
||||
|
||||
/*****************/
|
||||
/** Error Views **/
|
||||
/*****************/
|
||||
|
||||
div.dataview-error-box {
|
||||
width: 100%;
|
||||
min-height: 150px;
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
border: 4px dashed var(--background-secondary);
|
||||
}
|
||||
|
||||
.dataview-error-message {
|
||||
color: var(--text-muted);
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
/*************************/
|
||||
/** Additional Metadata **/
|
||||
/*************************/
|
||||
|
||||
.dataview.small-text {
|
||||
font-size: smaller;
|
||||
color: var(--text-muted);
|
||||
margin-left: 3px;
|
||||
}
|
||||
|
||||
.dataview.small-text::before {
|
||||
content: "(";
|
||||
}
|
||||
|
||||
.dataview.small-text::after {
|
||||
content: ")";
|
||||
}
|
||||
39
.obsidian/plugins/obsidian-day-planner/data.json
vendored
Normal file
39
.obsidian/plugins/obsidian-day-planner/data.json
vendored
Normal file
@ -0,0 +1,39 @@
|
||||
{
|
||||
"snapStepMinutes": 10,
|
||||
"progressIndicator": "bar",
|
||||
"showTaskNotification": false,
|
||||
"zoomLevel": 2,
|
||||
"timelineIcon": "calendar-with-checkmark",
|
||||
"endLabel": "All done",
|
||||
"startHour": 6,
|
||||
"timelineDateFormat": "YYYY-MM-DD",
|
||||
"centerNeedle": false,
|
||||
"plannerHeading": "Day planner",
|
||||
"plannerHeadingLevel": 1,
|
||||
"timelineColored": false,
|
||||
"timelineStartColor": "#006466",
|
||||
"timelineEndColor": "#4d194d",
|
||||
"timestampFormat": "HH:mm",
|
||||
"hourFormat": "H",
|
||||
"dataviewSource": "",
|
||||
"extendDurationUntilNext": false,
|
||||
"defaultDurationMinutes": 30,
|
||||
"minimalDurationMinutes": 10,
|
||||
"showTimestampInTaskBlock": false,
|
||||
"showUncheduledTasks": true,
|
||||
"showUnscheduledNestedTasks": true,
|
||||
"showNow": true,
|
||||
"showNext": true,
|
||||
"pluginVersion": "0.27.0",
|
||||
"showCompletedTasks": true,
|
||||
"showSubtasksInTaskBlocks": true,
|
||||
"icals": [],
|
||||
"colorOverrides": [],
|
||||
"releaseNotes": true,
|
||||
"taskStatusOnCreation": " ",
|
||||
"eventFormatOnCreation": "task",
|
||||
"sortTasksInPlanAfterEdit": false,
|
||||
"firstDayOfWeek": "monday",
|
||||
"multiDayRange": "3-days",
|
||||
"showTimeTracker": false
|
||||
}
|
||||
412
.obsidian/plugins/obsidian-day-planner/main.js
vendored
Normal file
412
.obsidian/plugins/obsidian-day-planner/main.js
vendored
Normal file
File diff suppressed because one or more lines are too long
11
.obsidian/plugins/obsidian-day-planner/manifest.json
vendored
Normal file
11
.obsidian/plugins/obsidian-day-planner/manifest.json
vendored
Normal file
@ -0,0 +1,11 @@
|
||||
{
|
||||
"id": "obsidian-day-planner",
|
||||
"name": "Day Planner",
|
||||
"version": "0.27.0",
|
||||
"minAppVersion": "0.16.0",
|
||||
"description": "A day planner with clean UI and readable syntax",
|
||||
"author": "James Lynch, continued by Ivan Lednev",
|
||||
"authorUrl": "https://github.com/ivan-lednev",
|
||||
"fundingUrl": "https://www.buymeacoffee.com/machineelf",
|
||||
"isDesktopOnly": false
|
||||
}
|
||||
9
.obsidian/plugins/obsidian-day-planner/styles.css
vendored
Normal file
9
.obsidian/plugins/obsidian-day-planner/styles.css
vendored
Normal file
File diff suppressed because one or more lines are too long
57
.obsidian/plugins/obsidian-git/data.json
vendored
Normal file
57
.obsidian/plugins/obsidian-git/data.json
vendored
Normal file
@ -0,0 +1,57 @@
|
||||
{
|
||||
"commitMessage": "vault backup: {{date}}",
|
||||
"commitDateFormat": "YYYY-MM-DD HH:mm:ss",
|
||||
"autoSaveInterval": 0,
|
||||
"autoPushInterval": 0,
|
||||
"autoPullInterval": 0,
|
||||
"autoPullOnBoot": false,
|
||||
"disablePush": false,
|
||||
"pullBeforePush": true,
|
||||
"disablePopups": false,
|
||||
"disablePopupsForNoChanges": false,
|
||||
"listChangedFilesInMessageBody": false,
|
||||
"showStatusBar": true,
|
||||
"updateSubmodules": false,
|
||||
"syncMethod": "merge",
|
||||
"customMessageOnAutoBackup": false,
|
||||
"autoBackupAfterFileChange": false,
|
||||
"treeStructure": false,
|
||||
"refreshSourceControl": true,
|
||||
"basePath": "",
|
||||
"differentIntervalCommitAndPush": false,
|
||||
"changedFilesInStatusBar": false,
|
||||
"showedMobileNotice": true,
|
||||
"refreshSourceControlTimer": 7000,
|
||||
"showBranchStatusBar": true,
|
||||
"setLastSaveToLastCommit": false,
|
||||
"submoduleRecurseCheckout": false,
|
||||
"gitDir": "",
|
||||
"showFileMenu": true,
|
||||
"authorInHistoryView": "hide",
|
||||
"dateInHistoryView": false,
|
||||
"diffStyle": "split",
|
||||
"lineAuthor": {
|
||||
"show": false,
|
||||
"followMovement": "inactive",
|
||||
"authorDisplay": "initials",
|
||||
"showCommitHash": false,
|
||||
"dateTimeFormatOptions": "date",
|
||||
"dateTimeFormatCustomString": "YYYY-MM-DD HH:mm",
|
||||
"dateTimeTimezone": "viewer-local",
|
||||
"coloringMaxAge": "1y",
|
||||
"colorNew": {
|
||||
"r": 255,
|
||||
"g": 150,
|
||||
"b": 150
|
||||
},
|
||||
"colorOld": {
|
||||
"r": 120,
|
||||
"g": 160,
|
||||
"b": 255
|
||||
},
|
||||
"textColorCss": "var(--text-muted)",
|
||||
"ignoreWhitespace": false,
|
||||
"gutterSpacingFallbackLength": 5
|
||||
},
|
||||
"autoCommitMessage": "vault backup: {{date}}"
|
||||
}
|
||||
416
.obsidian/plugins/obsidian-git/main.js
vendored
Normal file
416
.obsidian/plugins/obsidian-git/main.js
vendored
Normal file
File diff suppressed because one or more lines are too long
10
.obsidian/plugins/obsidian-git/manifest.json
vendored
Normal file
10
.obsidian/plugins/obsidian-git/manifest.json
vendored
Normal file
@ -0,0 +1,10 @@
|
||||
{
|
||||
"author": "Vinzent",
|
||||
"authorUrl": "https://github.com/Vinzent03",
|
||||
"id": "obsidian-git",
|
||||
"name": "Git",
|
||||
"description": "Integrate Git version control with automatic backup and other advanced features.",
|
||||
"isDesktopOnly": false,
|
||||
"fundingUrl": "https://ko-fi.com/vinzent",
|
||||
"version": "2.32.1"
|
||||
}
|
||||
23
.obsidian/plugins/obsidian-git/obsidian_askpass.sh
vendored
Executable file
23
.obsidian/plugins/obsidian-git/obsidian_askpass.sh
vendored
Executable file
@ -0,0 +1,23 @@
|
||||
#!/bin/sh
|
||||
|
||||
PROMPT="$1"
|
||||
TEMP_FILE="$OBSIDIAN_GIT_CREDENTIALS_INPUT"
|
||||
|
||||
cleanup() {
|
||||
rm -f "$TEMP_FILE" "$TEMP_FILE.response"
|
||||
}
|
||||
trap cleanup EXIT
|
||||
|
||||
echo "$PROMPT" > "$TEMP_FILE"
|
||||
|
||||
while [ ! -e "$TEMP_FILE.response" ]; do
|
||||
if [ ! -e "$TEMP_FILE" ]; then
|
||||
echo "Trigger file got removed: Abort" >&2
|
||||
exit 1
|
||||
fi
|
||||
sleep 0.1
|
||||
done
|
||||
|
||||
RESPONSE=$(cat "$TEMP_FILE.response")
|
||||
|
||||
echo "$RESPONSE"
|
||||
576
.obsidian/plugins/obsidian-git/styles.css
vendored
Normal file
576
.obsidian/plugins/obsidian-git/styles.css
vendored
Normal file
@ -0,0 +1,576 @@
|
||||
@keyframes loading {
|
||||
0% {
|
||||
transform: rotate(0deg);
|
||||
}
|
||||
|
||||
100% {
|
||||
transform: rotate(360deg);
|
||||
}
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="git-view"] .button-border {
|
||||
border: 2px solid var(--interactive-accent);
|
||||
border-radius: var(--radius-s);
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="git-view"] .view-content {
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="git-history-view"] .view-content {
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
.loading > svg {
|
||||
animation: 2s linear infinite loading;
|
||||
transform-origin: 50% 50%;
|
||||
display: inline-block;
|
||||
}
|
||||
|
||||
.obsidian-git-center {
|
||||
margin: auto;
|
||||
text-align: center;
|
||||
width: 50%;
|
||||
}
|
||||
|
||||
.obsidian-git-textarea {
|
||||
display: block;
|
||||
margin-left: auto;
|
||||
margin-right: auto;
|
||||
}
|
||||
|
||||
.obsidian-git-disabled {
|
||||
opacity: 0.5;
|
||||
}
|
||||
|
||||
.obsidian-git-center-button {
|
||||
display: block;
|
||||
margin: 20px auto;
|
||||
}
|
||||
|
||||
.tooltip.mod-left {
|
||||
overflow-wrap: break-word;
|
||||
}
|
||||
|
||||
.tooltip.mod-right {
|
||||
overflow-wrap: break-word;
|
||||
}
|
||||
.git-tools {
|
||||
display: flex;
|
||||
margin-left: auto;
|
||||
}
|
||||
.git-tools .type {
|
||||
padding-left: var(--size-2-1);
|
||||
display: flex;
|
||||
align-items: center;
|
||||
justify-content: center;
|
||||
width: 11px;
|
||||
}
|
||||
|
||||
.git-tools .type[data-type="M"] {
|
||||
color: orange;
|
||||
}
|
||||
.git-tools .type[data-type="D"] {
|
||||
color: red;
|
||||
}
|
||||
.git-tools .buttons {
|
||||
display: flex;
|
||||
}
|
||||
.git-tools .buttons > * {
|
||||
padding: 0 0;
|
||||
height: auto;
|
||||
}
|
||||
|
||||
.is-active .git-tools .buttons > * {
|
||||
color: var(--nav-item-color-active);
|
||||
}
|
||||
|
||||
.git-author {
|
||||
color: var(--text-accent);
|
||||
}
|
||||
|
||||
.git-date {
|
||||
color: var(--text-accent);
|
||||
}
|
||||
|
||||
.git-ref {
|
||||
color: var(--text-accent);
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-d-none {
|
||||
display: none;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-wrapper {
|
||||
text-align: left;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-header {
|
||||
background-color: var(--background-primary);
|
||||
border-bottom: 1px solid var(--interactive-accent);
|
||||
font-family: var(--font-monospace);
|
||||
height: 35px;
|
||||
padding: 5px 10px;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-header,
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-stats {
|
||||
display: -webkit-box;
|
||||
display: -ms-flexbox;
|
||||
display: flex;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-stats {
|
||||
font-size: 14px;
|
||||
margin-left: auto;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-lines-added {
|
||||
border: 1px solid #b4e2b4;
|
||||
border-radius: 5px 0 0 5px;
|
||||
color: #399839;
|
||||
padding: 2px;
|
||||
text-align: right;
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-lines-deleted {
|
||||
border: 1px solid #e9aeae;
|
||||
border-radius: 0 5px 5px 0;
|
||||
color: #c33;
|
||||
margin-left: 1px;
|
||||
padding: 2px;
|
||||
text-align: left;
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-name-wrapper {
|
||||
-webkit-box-align: center;
|
||||
-ms-flex-align: center;
|
||||
align-items: center;
|
||||
display: -webkit-box;
|
||||
display: -ms-flexbox;
|
||||
display: flex;
|
||||
font-size: 15px;
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-name {
|
||||
overflow-x: hidden;
|
||||
text-overflow: ellipsis;
|
||||
white-space: nowrap;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-wrapper {
|
||||
border: 1px solid var(--background-modifier-border);
|
||||
border-radius: 3px;
|
||||
margin-bottom: 1em;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-collapse {
|
||||
-webkit-box-pack: end;
|
||||
-ms-flex-pack: end;
|
||||
-webkit-box-align: center;
|
||||
-ms-flex-align: center;
|
||||
align-items: center;
|
||||
border: 1px solid var(--background-modifier-border);
|
||||
border-radius: 3px;
|
||||
cursor: pointer;
|
||||
display: none;
|
||||
font-size: 12px;
|
||||
justify-content: flex-end;
|
||||
padding: 4px 8px;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-collapse.d2h-selected {
|
||||
background-color: #c8e1ff;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-collapse-input {
|
||||
margin: 0 4px 0 0;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-diff-table {
|
||||
border-collapse: collapse;
|
||||
font-family: Menlo, Consolas, monospace;
|
||||
font-size: 13px;
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-files-diff {
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-diff {
|
||||
overflow-y: hidden;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-side-diff {
|
||||
display: inline-block;
|
||||
margin-bottom: -8px;
|
||||
margin-right: -4px;
|
||||
overflow-x: scroll;
|
||||
overflow-y: hidden;
|
||||
width: 50%;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-line {
|
||||
padding: 0 8em;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-line,
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-side-line {
|
||||
display: inline-block;
|
||||
-webkit-user-select: none;
|
||||
-moz-user-select: none;
|
||||
-ms-user-select: none;
|
||||
user-select: none;
|
||||
white-space: nowrap;
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-side-line {
|
||||
padding: 0 4.5em;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-line-ctn {
|
||||
word-wrap: normal;
|
||||
background: none;
|
||||
display: inline-block;
|
||||
padding: 0;
|
||||
-webkit-user-select: text;
|
||||
-moz-user-select: text;
|
||||
-ms-user-select: text;
|
||||
user-select: text;
|
||||
vertical-align: middle;
|
||||
white-space: pre;
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.theme-light .workspace-leaf-content[data-type="diff-view"] .d2h-code-line del,
|
||||
.theme-light
|
||||
.workspace-leaf-content[data-type="diff-view"]
|
||||
.d2h-code-side-line
|
||||
del {
|
||||
background-color: #ffb6ba;
|
||||
}
|
||||
|
||||
.theme-dark .workspace-leaf-content[data-type="diff-view"] .d2h-code-line del,
|
||||
.theme-dark
|
||||
.workspace-leaf-content[data-type="diff-view"]
|
||||
.d2h-code-side-line
|
||||
del {
|
||||
background-color: #8d232881;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-line del,
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-line ins,
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-side-line del,
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-side-line ins {
|
||||
border-radius: 0.2em;
|
||||
display: inline-block;
|
||||
margin-top: -1px;
|
||||
text-decoration: none;
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
.theme-light .workspace-leaf-content[data-type="diff-view"] .d2h-code-line ins,
|
||||
.theme-light
|
||||
.workspace-leaf-content[data-type="diff-view"]
|
||||
.d2h-code-side-line
|
||||
ins {
|
||||
background-color: #97f295;
|
||||
text-align: left;
|
||||
}
|
||||
|
||||
.theme-dark .workspace-leaf-content[data-type="diff-view"] .d2h-code-line ins,
|
||||
.theme-dark
|
||||
.workspace-leaf-content[data-type="diff-view"]
|
||||
.d2h-code-side-line
|
||||
ins {
|
||||
background-color: #1d921996;
|
||||
text-align: left;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-line-prefix {
|
||||
word-wrap: normal;
|
||||
background: none;
|
||||
display: inline;
|
||||
padding: 0;
|
||||
white-space: pre;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .line-num1 {
|
||||
float: left;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .line-num1,
|
||||
.workspace-leaf-content[data-type="diff-view"] .line-num2 {
|
||||
-webkit-box-sizing: border-box;
|
||||
box-sizing: border-box;
|
||||
overflow: hidden;
|
||||
padding: 0 0.5em;
|
||||
text-overflow: ellipsis;
|
||||
width: 3.5em;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .line-num2 {
|
||||
float: right;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-linenumber {
|
||||
background-color: var(--background-primary);
|
||||
border: solid var(--background-modifier-border);
|
||||
border-width: 0 1px;
|
||||
-webkit-box-sizing: border-box;
|
||||
box-sizing: border-box;
|
||||
color: var(--text-muted);
|
||||
cursor: pointer;
|
||||
display: inline-block;
|
||||
position: absolute;
|
||||
text-align: right;
|
||||
width: 7.5em;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-linenumber:after {
|
||||
content: "\200b";
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-side-linenumber {
|
||||
background-color: var(--background-primary);
|
||||
border: solid var(--background-modifier-border);
|
||||
border-width: 0 1px;
|
||||
-webkit-box-sizing: border-box;
|
||||
box-sizing: border-box;
|
||||
color: var(--text-muted);
|
||||
cursor: pointer;
|
||||
display: inline-block;
|
||||
overflow: hidden;
|
||||
padding: 0 0.5em;
|
||||
position: absolute;
|
||||
text-align: right;
|
||||
text-overflow: ellipsis;
|
||||
width: 4em;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-diff-tbody tr {
|
||||
position: relative;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-side-linenumber:after {
|
||||
content: "\200b";
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-side-emptyplaceholder,
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-emptyplaceholder {
|
||||
background-color: var(--background-primary);
|
||||
border-color: var(--background-modifier-border);
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-line-prefix,
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-linenumber,
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-side-linenumber,
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-emptyplaceholder {
|
||||
-webkit-user-select: none;
|
||||
-moz-user-select: none;
|
||||
-ms-user-select: none;
|
||||
user-select: none;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-linenumber,
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-code-side-linenumber {
|
||||
direction: rtl;
|
||||
}
|
||||
|
||||
.theme-light .workspace-leaf-content[data-type="diff-view"] .d2h-del {
|
||||
background-color: #fee8e9;
|
||||
border-color: #e9aeae;
|
||||
}
|
||||
|
||||
.theme-light .workspace-leaf-content[data-type="diff-view"] .d2h-ins {
|
||||
background-color: #dfd;
|
||||
border-color: #b4e2b4;
|
||||
}
|
||||
|
||||
.theme-dark .workspace-leaf-content[data-type="diff-view"] .d2h-del {
|
||||
background-color: #521b1d83;
|
||||
border-color: #691d1d73;
|
||||
}
|
||||
|
||||
.theme-dark .workspace-leaf-content[data-type="diff-view"] .d2h-ins {
|
||||
background-color: rgba(30, 71, 30, 0.5);
|
||||
border-color: #13501381;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-info {
|
||||
background-color: var(--background-primary);
|
||||
border-color: var(--background-modifier-border);
|
||||
color: var(--text-normal);
|
||||
}
|
||||
|
||||
.theme-light
|
||||
.workspace-leaf-content[data-type="diff-view"]
|
||||
.d2h-file-diff
|
||||
.d2h-del.d2h-change {
|
||||
background-color: #fdf2d0;
|
||||
}
|
||||
|
||||
.theme-dark
|
||||
.workspace-leaf-content[data-type="diff-view"]
|
||||
.d2h-file-diff
|
||||
.d2h-del.d2h-change {
|
||||
background-color: #55492480;
|
||||
}
|
||||
|
||||
.theme-light
|
||||
.workspace-leaf-content[data-type="diff-view"]
|
||||
.d2h-file-diff
|
||||
.d2h-ins.d2h-change {
|
||||
background-color: #ded;
|
||||
}
|
||||
|
||||
.theme-dark
|
||||
.workspace-leaf-content[data-type="diff-view"]
|
||||
.d2h-file-diff
|
||||
.d2h-ins.d2h-change {
|
||||
background-color: rgba(37, 78, 37, 0.418);
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-list-wrapper {
|
||||
margin-bottom: 10px;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-list-wrapper a {
|
||||
color: #3572b0;
|
||||
text-decoration: none;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"]
|
||||
.d2h-file-list-wrapper
|
||||
a:visited {
|
||||
color: #3572b0;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-list-header {
|
||||
text-align: left;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-list-title {
|
||||
font-weight: 700;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-list-line {
|
||||
display: -webkit-box;
|
||||
display: -ms-flexbox;
|
||||
display: flex;
|
||||
text-align: left;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-list {
|
||||
display: block;
|
||||
list-style: none;
|
||||
margin: 0;
|
||||
padding: 0;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-list > li {
|
||||
border-bottom: 1px solid var(--background-modifier-border);
|
||||
margin: 0;
|
||||
padding: 5px 10px;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-list > li:last-child {
|
||||
border-bottom: none;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-file-switch {
|
||||
cursor: pointer;
|
||||
display: none;
|
||||
font-size: 10px;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-icon {
|
||||
fill: currentColor;
|
||||
margin-right: 10px;
|
||||
vertical-align: middle;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-deleted {
|
||||
color: #c33;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-added {
|
||||
color: #399839;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-changed {
|
||||
color: #d0b44c;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-moved {
|
||||
color: #3572b0;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-tag {
|
||||
background-color: var(--background-primary);
|
||||
display: -webkit-box;
|
||||
display: -ms-flexbox;
|
||||
display: flex;
|
||||
font-size: 10px;
|
||||
margin-left: 5px;
|
||||
padding: 0 2px;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-deleted-tag {
|
||||
border: 2px solid #c33;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-added-tag {
|
||||
border: 1px solid #399839;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-changed-tag {
|
||||
border: 1px solid #d0b44c;
|
||||
}
|
||||
|
||||
.workspace-leaf-content[data-type="diff-view"] .d2h-moved-tag {
|
||||
border: 1px solid #3572b0;
|
||||
}
|
||||
|
||||
/* ====================== Line Authoring Information ====================== */
|
||||
|
||||
.cm-gutterElement.obs-git-blame-gutter {
|
||||
/* Add background color to spacing inbetween and around the gutter for better aesthetics */
|
||||
border-width: 0px 2px 0.2px 2px;
|
||||
border-style: solid;
|
||||
border-color: var(--background-secondary);
|
||||
background-color: var(--background-secondary);
|
||||
}
|
||||
|
||||
.cm-gutterElement.obs-git-blame-gutter > div,
|
||||
.line-author-settings-preview {
|
||||
/* delegate text color to settings */
|
||||
color: var(--obs-git-gutter-text);
|
||||
font-family: monospace;
|
||||
height: 100%; /* ensure, that age-based background color occupies entire parent */
|
||||
text-align: right;
|
||||
padding: 0px 6px 0px 6px;
|
||||
white-space: pre; /* Keep spaces and do not collapse them. */
|
||||
}
|
||||
|
||||
@media (max-width: 800px) {
|
||||
/* hide git blame gutter not to superpose text */
|
||||
.cm-gutterElement.obs-git-blame-gutter {
|
||||
display: none;
|
||||
}
|
||||
}
|
||||
|
||||
.git-unified-diff-view,
|
||||
.git-split-diff-view .cm-deletedLine .cm-changedText {
|
||||
background-color: #ee443330;
|
||||
}
|
||||
|
||||
.git-unified-diff-view,
|
||||
.git-split-diff-view .cm-insertedLine .cm-changedText {
|
||||
background-color: #22bb2230;
|
||||
}
|
||||
228
.obsidian/plugins/obsidian-importer/main.js
vendored
Normal file
228
.obsidian/plugins/obsidian-importer/main.js
vendored
Normal file
File diff suppressed because one or more lines are too long
10
.obsidian/plugins/obsidian-importer/manifest.json
vendored
Normal file
10
.obsidian/plugins/obsidian-importer/manifest.json
vendored
Normal file
@ -0,0 +1,10 @@
|
||||
{
|
||||
"id": "obsidian-importer",
|
||||
"name": "Importer",
|
||||
"version": "1.6.19",
|
||||
"minAppVersion": "0.15.0",
|
||||
"description": "Import data from Notion, Evernote, Apple Notes, Microsoft OneNote, Google Keep, Bear, Roam, and HTML files.",
|
||||
"author": "Obsidian",
|
||||
"authorUrl": "https://obsidian.md",
|
||||
"isDesktopOnly": false
|
||||
}
|
||||
87
.obsidian/plugins/obsidian-importer/styles.css
vendored
Normal file
87
.obsidian/plugins/obsidian-importer/styles.css
vendored
Normal file
@ -0,0 +1,87 @@
|
||||
.modal.mod-importer {
|
||||
max-height: var(--modal-height);
|
||||
padding: var(--size-4-4) 0 0 0;
|
||||
position: relative;
|
||||
overflow: hidden;
|
||||
}
|
||||
.modal.mod-importer .modal-title {
|
||||
padding: 0 var(--size-4-4);
|
||||
}
|
||||
.modal.mod-importer .modal-content {
|
||||
overflow: auto;
|
||||
padding: var(--size-4-4);
|
||||
margin-bottom: calc(var(--input-height) + var(--size-4-8));
|
||||
border-top: var(--border-width) solid var(--background-modifier-border);
|
||||
}
|
||||
.modal.mod-importer .modal-button-container {
|
||||
margin: 0 0 0 calc(var(--size-4-4) * -1);
|
||||
padding: var(--size-4-4);
|
||||
gap: var(--size-4-2);
|
||||
position: absolute;
|
||||
bottom: 0;
|
||||
background-color: var(--background-primary);
|
||||
border-top: var(--border-width) solid var(--background-modifier-border);
|
||||
width: 100%;
|
||||
}
|
||||
|
||||
.importer-progress-bar {
|
||||
width: 100%;
|
||||
height: 8px;
|
||||
background-color: var(--background-secondary);
|
||||
overflow: hidden;
|
||||
box-shadow: inset 0px 0px 0px 1px var(--background-modifier-border);
|
||||
border-radius: var(--radius-s);
|
||||
}
|
||||
|
||||
.importer-progress-bar-inner {
|
||||
width: 0;
|
||||
height: 100%;
|
||||
background-color: var(--interactive-accent);
|
||||
}
|
||||
|
||||
.importer-status {
|
||||
white-space: nowrap;
|
||||
overflow: hidden;
|
||||
text-overflow: ellipsis;
|
||||
padding: var(--size-4-2) 0;
|
||||
}
|
||||
|
||||
.importer-stats-container {
|
||||
display: flex;
|
||||
justify-content: space-evenly;
|
||||
margin-top: var(--size-4-5);
|
||||
margin-bottom: var(--size-4-5);
|
||||
}
|
||||
|
||||
.importer-stat {
|
||||
text-align: center;
|
||||
}
|
||||
|
||||
.importer-stat-count {
|
||||
font-size: var(--font-ui-large);
|
||||
}
|
||||
|
||||
.importer-log {
|
||||
overflow: auto;
|
||||
flex-grow: 1;
|
||||
font-family: var(--font-monospace);
|
||||
font-size: var(--font-ui-smaller);
|
||||
color: var(--text-muted);
|
||||
border: 1px solid var(--background-modifier-border);
|
||||
padding: var(--size-4-4);
|
||||
background-color: var(--background-secondary);
|
||||
border-radius: var(--radius-s);
|
||||
max-height: 300px;
|
||||
user-select: text;
|
||||
}
|
||||
|
||||
.importer-log .list-item {
|
||||
display: inline-block;
|
||||
line-height: var(--line-height-normal);
|
||||
white-space: pre;
|
||||
margin: var(--size-2-1);
|
||||
}
|
||||
|
||||
.importer-error {
|
||||
color: var(--text-error);
|
||||
}
|
||||
153
.obsidian/plugins/obsidian-kanban/main.js
vendored
Normal file
153
.obsidian/plugins/obsidian-kanban/main.js
vendored
Normal file
File diff suppressed because one or more lines are too long
11
.obsidian/plugins/obsidian-kanban/manifest.json
vendored
Normal file
11
.obsidian/plugins/obsidian-kanban/manifest.json
vendored
Normal file
@ -0,0 +1,11 @@
|
||||
{
|
||||
"id": "obsidian-kanban",
|
||||
"name": "Kanban",
|
||||
"version": "2.0.51",
|
||||
"minAppVersion": "1.0.0",
|
||||
"description": "Create markdown-backed Kanban boards in Obsidian.",
|
||||
"author": "mgmeyers",
|
||||
"authorUrl": "https://github.com/mgmeyers/obsidian-kanban",
|
||||
"helpUrl": "https://publish.obsidian.md/kanban/Obsidian+Kanban+Plugin",
|
||||
"isDesktopOnly": false
|
||||
}
|
||||
1
.obsidian/plugins/obsidian-kanban/styles.css
vendored
Normal file
1
.obsidian/plugins/obsidian-kanban/styles.css
vendored
Normal file
File diff suppressed because one or more lines are too long
3
.obsidian/templates.json
vendored
Normal file
3
.obsidian/templates.json
vendored
Normal file
@ -0,0 +1,3 @@
|
||||
{
|
||||
"folder": "templates"
|
||||
}
|
||||
10
.obsidian/types.json
vendored
Normal file
10
.obsidian/types.json
vendored
Normal file
@ -0,0 +1,10 @@
|
||||
{
|
||||
"types": {
|
||||
"aliases": "aliases",
|
||||
"cssclasses": "multitext",
|
||||
"tags": "tags",
|
||||
"date": "date",
|
||||
"describe": "text",
|
||||
"bookName": "text"
|
||||
}
|
||||
}
|
||||
281
.obsidian/workspace.json
vendored
Normal file
281
.obsidian/workspace.json
vendored
Normal file
@ -0,0 +1,281 @@
|
||||
{
|
||||
"main": {
|
||||
"id": "089e59043add2840",
|
||||
"type": "split",
|
||||
"children": [
|
||||
{
|
||||
"id": "779ce2da10685674",
|
||||
"type": "tabs",
|
||||
"children": [
|
||||
{
|
||||
"id": "232557ff1641c4e1",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "markdown",
|
||||
"state": {
|
||||
"file": "demo/三个运动定律.md",
|
||||
"mode": "source",
|
||||
"source": false,
|
||||
"backlinks": true,
|
||||
"backlinkOpts": {
|
||||
"collapseAll": false,
|
||||
"extraContext": false,
|
||||
"sortOrder": "alphabetical",
|
||||
"showSearch": false,
|
||||
"searchQuery": "",
|
||||
"backlinkCollapsed": false,
|
||||
"unlinkedCollapsed": true
|
||||
}
|
||||
},
|
||||
"icon": "lucide-file",
|
||||
"title": "三个运动定律"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"direction": "vertical"
|
||||
},
|
||||
"left": {
|
||||
"id": "f02b8f0203ad6798",
|
||||
"type": "split",
|
||||
"children": [
|
||||
{
|
||||
"id": "9aba6106d1ffe45f",
|
||||
"type": "tabs",
|
||||
"children": [
|
||||
{
|
||||
"id": "76751a9e5608cd89",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "file-explorer",
|
||||
"state": {
|
||||
"sortOrder": "alphabetical",
|
||||
"autoReveal": false
|
||||
},
|
||||
"icon": "lucide-folder-closed",
|
||||
"title": "文件列表"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "f7237a916e3ce339",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "search",
|
||||
"state": {
|
||||
"query": "",
|
||||
"matchingCase": false,
|
||||
"explainSearch": false,
|
||||
"collapseAll": false,
|
||||
"extraContext": false,
|
||||
"sortOrder": "alphabetical"
|
||||
},
|
||||
"icon": "lucide-search",
|
||||
"title": "搜索"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "0333b2220dd4771e",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "bookmarks",
|
||||
"state": {},
|
||||
"icon": "lucide-bookmark",
|
||||
"title": "书签"
|
||||
}
|
||||
}
|
||||
]
|
||||
}
|
||||
],
|
||||
"direction": "horizontal",
|
||||
"width": 300
|
||||
},
|
||||
"right": {
|
||||
"id": "ed0ff6ed65987e7a",
|
||||
"type": "split",
|
||||
"children": [
|
||||
{
|
||||
"id": "07d6c74723a4610e",
|
||||
"type": "tabs",
|
||||
"children": [
|
||||
{
|
||||
"id": "0abf9d6487bcfaea",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "backlink",
|
||||
"state": {
|
||||
"file": "freqtrade 理解消化.md",
|
||||
"collapseAll": false,
|
||||
"extraContext": false,
|
||||
"sortOrder": "alphabetical",
|
||||
"showSearch": false,
|
||||
"searchQuery": "",
|
||||
"backlinkCollapsed": false,
|
||||
"unlinkedCollapsed": true
|
||||
},
|
||||
"icon": "links-coming-in",
|
||||
"title": "freqtrade 理解消化 的反向链接列表"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "5ebaa2ee70419203",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "outgoing-link",
|
||||
"state": {
|
||||
"file": "随便/甘特图 流程图 各种图.md",
|
||||
"linksCollapsed": false,
|
||||
"unlinkedCollapsed": true
|
||||
},
|
||||
"icon": "links-going-out",
|
||||
"title": "甘特图 流程图 各种图 的出链列表"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "d070d7c7c7fd043e",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "tag",
|
||||
"state": {
|
||||
"sortOrder": "frequency",
|
||||
"useHierarchy": true,
|
||||
"showSearch": false,
|
||||
"searchQuery": ""
|
||||
},
|
||||
"icon": "lucide-tags",
|
||||
"title": "标签"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "61b570e21fca7b37",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "outline",
|
||||
"state": {
|
||||
"file": "AI相关/未命名.canvas",
|
||||
"followCursor": true,
|
||||
"showSearch": true,
|
||||
"searchQuery": ""
|
||||
},
|
||||
"icon": "lucide-list",
|
||||
"title": "未命名 的大纲"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "24165256c8d78be3",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "planner-timeline",
|
||||
"state": {},
|
||||
"icon": "lucide-file",
|
||||
"title": "插件不再活动"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "5369911ec89f6d64",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "planner-timeline",
|
||||
"state": {},
|
||||
"icon": "lucide-file",
|
||||
"title": "插件不再活动"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "cbd56a01a6cbccd6",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "git-view",
|
||||
"state": {},
|
||||
"icon": "git-pull-request",
|
||||
"title": "Source Control"
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "0974c29258d370bd",
|
||||
"type": "leaf",
|
||||
"state": {
|
||||
"type": "planner-timeline",
|
||||
"state": {},
|
||||
"icon": "calendar-with-checkmark",
|
||||
"title": "Timeline"
|
||||
}
|
||||
}
|
||||
],
|
||||
"currentTab": 6
|
||||
}
|
||||
],
|
||||
"direction": "horizontal",
|
||||
"width": 200
|
||||
},
|
||||
"left-ribbon": {
|
||||
"hiddenItems": {
|
||||
"switcher:打开快速切换": false,
|
||||
"graph:查看关系图谱": false,
|
||||
"canvas:新建白板": false,
|
||||
"daily-notes:打开/创建今天的日记": false,
|
||||
"templates:插入模板": false,
|
||||
"command-palette:打开命令面板": false,
|
||||
"markdown-importer:打开 Markdown 格式转换器": false,
|
||||
"obsidian-day-planner:Open Timeline": false,
|
||||
"obsidian-day-planner:Open Multi-Day View": false,
|
||||
"obsidian-importer:Open Importer": false,
|
||||
"obsidian-kanban:创建新看板": false,
|
||||
"obsidian-git:Open Git source control": false
|
||||
}
|
||||
},
|
||||
"active": "232557ff1641c4e1",
|
||||
"lastOpenFiles": [
|
||||
"`freqtrade.md",
|
||||
"demo/三个运动定律.md",
|
||||
"Pasted image 20250204021453.png",
|
||||
"freqtrade_理解消化.md",
|
||||
"freqtrade_基础.md",
|
||||
"Pasted image 20250222113205.png",
|
||||
"backtrader.md",
|
||||
"backtrader 事件回调函数.md",
|
||||
"backtrader_&_okx.md",
|
||||
"未命名.canvas",
|
||||
"core/go_wire 循环依赖.md",
|
||||
"生成像素风格图片 (4).png",
|
||||
"templates/阅读笔记.md",
|
||||
"n8n/Getting_started.md",
|
||||
"core/循环依赖相关对话.md",
|
||||
"avante/neo-vim_ai 编程辅助插件-avante_扩展使用指南.md",
|
||||
"随便/甘特图流程图各种图.md",
|
||||
"populate_indicators函数.md",
|
||||
"freqtrade.md",
|
||||
"populate_indicators.md",
|
||||
"populate_indicator.md",
|
||||
"AI相关/英文文章可读性量化.md",
|
||||
"core/restruct.md",
|
||||
"车位诉讼策略.md",
|
||||
"策略.md",
|
||||
"2025-03-21.md",
|
||||
"2025-02-02 要做的事情.md",
|
||||
"n8n/如何触发.md",
|
||||
"core/循环依赖问题.md",
|
||||
"AI相关/未命名.canvas",
|
||||
"未命名 4.canvas",
|
||||
"templates",
|
||||
"未命名 3.canvas",
|
||||
"未命名 2.canvas",
|
||||
"法律",
|
||||
"未命名 1.canvas",
|
||||
"blingo",
|
||||
"Pasted image 20250222115616.png",
|
||||
"Pasted image 20250204022601.png",
|
||||
"core",
|
||||
"avante",
|
||||
"demo",
|
||||
"学英语",
|
||||
"n8n",
|
||||
"随便",
|
||||
"要做的事情",
|
||||
"AA5B1439-F6D4-4633-8F3B-A30A2538D674_1_105_c.jpeg",
|
||||
"AA5B1439-F6D4-4633-8F3B-A30A2538D674_1_105_c 2.jpeg",
|
||||
"AA5B1439-F6D4-4633-8F3B-A30A2538D674_1_105_c 1.jpeg",
|
||||
"代订附加产品(服务包)发票_订单31324101513471184053056 3_副本.png",
|
||||
"【飞猪】订单7224154890106-机票款凭证 报销凭证 3_副本.png"
|
||||
]
|
||||
}
|
||||
9
2025-02-02 要做的事情.md
Normal file
9
2025-02-02 要做的事情.md
Normal file
@ -0,0 +1,9 @@
|
||||
未来一段时间要做的
|
||||
|
||||
备份:
|
||||
|
||||
- 这个程序 obsidian
|
||||
- elasticsearch 备份,并验证
|
||||
- 验证elasticsearch在arm上恢复正常运行
|
||||
- 验证emma和juicy的image备份
|
||||
- 备份gitea.zjmud.xyz
|
||||
0
2025-03-21.md
Normal file
0
2025-03-21.md
Normal file
3
AI相关/AnythinyLLM key.md
Normal file
3
AI相关/AnythinyLLM key.md
Normal file
@ -0,0 +1,3 @@
|
||||
|
||||
FY2D6B4-EJQ42QN-GRC4N29-ZDQQV1B
|
||||
61HJMSC-BZ4MDN1-HW0YF9P-SGTC0DY
|
||||
9
AI相关/未命名.canvas
Normal file
9
AI相关/未命名.canvas
Normal file
@ -0,0 +1,9 @@
|
||||
{
|
||||
"nodes":[
|
||||
{"id":"9306023bffaeeedd","type":"text","text":"asdf\n","x":-125,"y":-30,"width":250,"height":60},
|
||||
{"id":"b4f8330cfa70b1b4","x":-125,"y":100,"width":285,"height":60,"type":"text","text":"有了这个可以不用xmind了"}
|
||||
],
|
||||
"edges":[
|
||||
{"id":"7c6383beb8a55e88","fromNode":"9306023bffaeeedd","fromSide":"right","toNode":"b4f8330cfa70b1b4","toSide":"right"}
|
||||
]
|
||||
}
|
||||
596
AI相关/英文文章可读性量化.md
Normal file
596
AI相关/英文文章可读性量化.md
Normal file
@ -0,0 +1,596 @@
|
||||
|
||||
[[高中英语词汇]]
|
||||
|
||||
哪儿能找到大量的英文短文的,类似新概念之类的,最好是能通过api或者rss订阅来获取的
|
||||
|
||||
基于 13 个搜索来源
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
以下是一些可以找到大量类似《新概念》英文短文,且能通过 API 或 RSS 订阅获取的途径:
|
||||
|
||||
### 通过 API 获取
|
||||
|
||||
|
||||
|
||||
- **深蓝阅读(BlueReader)**3:该平台可以将内容展现在自己的网站上,丰富网站内容。它支持订阅 RSS 或任意网站链接等,能实现无缝订阅,可订阅国内外内容,适合追求个性化阅读体验的用户。
|
||||
- **扇贝阅读**11:扇贝阅读有自己的 APP 和网站平台,为用户推送原汁原味的英语短文和原著。它有一定概率提供 API 供开发者接入,不过通常需要与官方沟通合作,其提供的文章涵盖热点、科技、商业、科普等多个领域。
|
||||
|
||||
### 通过 RSS 订阅获取
|
||||
|
||||
|
||||
|
||||
- **BBC Learning English**:英国广播公司旗下的在线英语学习平台,提供大量优质英语学习资源和外刊文章等内容。在其网站上可能存在 RSS 订阅链接,可使用 RSS 阅读器订阅,获取各类英文短文,内容包括新闻、文化、教育等,语言地道,难度多样,适合不同水平的英语学习者。
|
||||
- **《纽约时报》《华盛顿邮报》等外刊网站**:这些著名外刊网站有丰富的英文文章,涵盖政治、经济、文化、社会等各个领域。通常在网站上能找到 RSS 订阅链接,通过 RSS 阅读器订阅后,可及时获取最新文章。文章具有较高的语言水平和阅读价值,有助于提高英语阅读能力和了解国际时事。
|
||||
- **Feedly 等聚合平台**:可以在这类平台上搜索和订阅大量英文网站的 RSS 源,包括许多提供英文短文的博客、杂志网站等。用户能在一个平台上整合阅读多个来源的内容,方便快捷地获取丰富的英文短文资源。
|
||||
|
||||
|
||||
|
||||
另外,若网站本身不支持 RSS 订阅,还可通过 RSSHub、RSS-Proxy 等工具生成 RSS 订阅源12。
|
||||
|
||||
quora.com
|
||||
|
||||
链接
|
||||
|
||||
这个网站是付费的吗
|
||||
|
||||
基于 3 个搜索来源
|
||||
|
||||

|
||||
|
||||
Quora 网站基本使用是免费的,但也有付费服务 Quora Plus,具体情况如下:
|
||||
|
||||
|
||||
|
||||
- **免费部分**:用户可以免费注册账号,在 Quora 上提问、回答问题、浏览大量公开的问题和答案,参与社区讨论等。通过免费账户,用户能够获取到各种领域的知识和信息,与其他用户交流互动,这也是 Quora 作为一个知识分享平台的核心功能体现。
|
||||
- **付费部分**:Quora 推出了 Quora Plus 订阅服务,每月收费 6.99 美元,或每年一次性支付 47.88 美元。订阅用户可以访问更多的文章和独特的故事,解锁独家内容并无限制地访问仅限订阅者的内容,还能享受无广告的浏览体验。平台会将订阅费用的 95% 分配给内容创作者。
|
||||
|
||||
quora.com
|
||||
|
||||
那么如果我想在quora上订阅非quora plus的笑话集锦该怎么找
|
||||
|
||||
基于 2 个搜索来源
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
在 Quora 上订阅非 Quora Plus 的笑话集锦可尝试以下方法:
|
||||
|
||||
|
||||
|
||||
- **利用话题搜索与关注**:登录 Quora 账号后,在搜索框中输入 “jokes”“funny stories” 等与笑话相关的关键词,系统会展示包含这些关键词的问题、回答和话题等内容。浏览搜索结果,找到那些专门收集和分享笑话的话题或问题,点击进入后关注该话题或问题,这样每当有新的笑话内容更新,你就会在自己的 Quora 动态中收到相关推送。比如搜索 “jokes”,会出现许多关于笑话的提问和回答,像 “How to tell a good joke” 等问题下可能会有很多用户分享有趣的笑话。
|
||||
- **寻找笑话主题的空间**:Quora 上有各种主题的空间,你可以通过搜索或在相关分类中查找专门用于分享笑话集锦的空间,比如 “Jokes, Humour & Funny stories” 空间。进入这些空间后,点击空间名称旁边的 “关注” 按钮,就能订阅该空间的内容,获取其中的笑话更新。
|
||||
- **关注笑话领域的用户**:搜索一些经常分享笑话或在幽默领域活跃的用户,查看他们的个人主页,若其内容符合你的需求,点击 “关注” 按钮。这些用户发布新的笑话内容时,你也能在动态中看到。比如有的用户专门收集和分享各种冷笑话,关注他们后就能定期看到新的冷笑话推送。
|
||||
|
||||
quora.com
|
||||
|
||||
Flesch-Kincaid analysis 是什么
|
||||
|
||||
Flesch-Kincaid analysis 即 “弗莱士 - 金凯德分析”,是一种用于评估文本难易程度的方法,以下从其定义、计算指标及应用场景等方面进行具体介绍:
|
||||
|
||||
### 定义与背景
|
||||
|
||||
|
||||
|
||||
- Flesch-Kincaid analysis 由鲁道夫・弗莱士(Rudolf Flesch)和 J. 彼得・金凯德(J. Peter Kincaid)开发。它基于文本的词汇和句子结构等要素,通过特定算法计算出一个数值,来反映文本对于读者的难易程度,常被用于教育、出版、语言学习等领域,帮助判断文本是否适合特定读者群体。
|
||||
|
||||
### 计算指标
|
||||
|
||||
|
||||
|
||||
- **Flesch 阅读易读性公式(Flesch Reading Ease formula)**:主要考虑文本中单词的平均音节数和句子的平均单词数。计算公式为:总单词数总句子数总音节数总单词数。得出的分数越高,文本越容易阅读。例如,分数在 90-100 之间表明文本非常容易理解,类似给小学生阅读的简单材料;而分数在 30-50 之间则表示文本较难,可能适合专业人士或具有较高阅读水平的读者。
|
||||
- **Flesch-Kincaid 年级水平公式(Flesch-Kincaid Grade Level formula)**:侧重于计算文本对应的美国年级水平。公式为:总单词数总句子数总音节数总单词数。计算结果表示文本大致适合的美国学校年级,比如结果为 8.0,就意味着该文本难度大致适合美国 8 年级学生阅读。
|
||||
|
||||
### 应用场景
|
||||
|
||||
|
||||
|
||||
- **教育领域**:教师可以使用 Flesch-Kincaid 分析来评估教材、阅读材料是否符合学生的学习水平,以便选择合适的教学资源,或根据分析结果对现有材料进行适当调整。
|
||||
- **出版行业**:编辑和出版商利用该分析来了解目标读者群体的阅读难度预期,对书稿进行评估和编辑,确保书籍能够被目标受众轻松理解,提高作品的市场适应性。
|
||||
- **语言学习**:学习者可以通过 Flesch-Kincaid 分析了解自己正在阅读或学习的文本难度,选择适合自己当前水平的材料,逐步提高语言能力。同时,语言培训机构也可以根据这一分析来设计课程和选择教材。
|
||||
|
||||
quora.com
|
||||
|
||||
有没有量化的算法来对文章进行Flesch-Kincaid analysis
|
||||
|
||||
Flesch-Kincaid 分析有量化的算法,常见的 Flesch 阅读易读性公式和 Flesch-Kincaid 年级水平公式上文已经提及,以下为你详细介绍计算步骤及示例:
|
||||
|
||||
### Flesch 阅读易读性公式
|
||||
|
||||
|
||||
|
||||
- **计算步骤**
|
||||
1. **统计总单词数**:统计文本中所有单词的数量。
|
||||
2. **统计总句子数**:计算文本中句子的数量,以句号、问号、感叹号等作为句子结束的标志。
|
||||
3. **统计总音节数**:对文本中每个单词的音节进行计数,然后求和。可根据单词的发音或一些音节划分规则来确定音节数,例如 “apple” 有两个音节,“computer” 有三个音节。
|
||||
4. **代入公式计算**:将统计得到的总单词数、总句子数和总音节数代入公式总单词数总句子数总音节数总单词数,得出 Flesch 阅读易读性分数。
|
||||
- **示例**:一篇文本有 200 个单词,10 个句子,总音节数为 300 个。首先计算总单词数总句子数,总音节数总单词数。然后代入公式可得:,该文本的 Flesch 阅读易读性分数为 59.635,属于中等难度水平。
|
||||
|
||||
### Flesch - Kincaid 年级水平公式
|
||||
|
||||
|
||||
|
||||
- **计算步骤**
|
||||
1. **同样需统计总单词数、总句子数和总音节数**:统计方法与上述 Flesch 阅读易读性公式中的统计方法一致。
|
||||
2. **代入公式计算**:将统计数据代入公式总单词数总句子数总音节数总单词数,得到 Flesch - Kincaid 年级水平值。
|
||||
- **示例**:对于上述同样的文本示例,总单词数总句子数,总音节数总单词数,代入公式可得:,表明该文本的难度大致适合美国 9.91 年级的学生阅读。
|
||||
|
||||
quora.com
|
||||
|
||||
那么如果我有一篇文章,然后想得到一个Flesch-Kincaid 分析, 让python干这件事情, 需要自己写代码还是有现成的库
|
||||
|
||||
在 Python 中,有现成的库可以进行 Flesch-Kincaid 分析,无需完全自己写代码,以下介绍两个常用库:
|
||||
|
||||
### textstat 库
|
||||
|
||||
|
||||
|
||||
- **安装**:可以使用`pip install textstat`命令进行安装。
|
||||
- **使用示例**
|
||||
|
||||
|
||||
|
||||
收起
|
||||
|
||||
python
|
||||
|
||||
```
|
||||
import textstat
|
||||
|
||||
text = "This is a sample text. It contains some words and sentences."
|
||||
flesch_reading_ease = textstat.flesch_reading_ease(text)
|
||||
flesch_kincaid_grade = textstat.flesch_kincaid_grade(text)
|
||||
|
||||
print("Flesch Reading Ease:", flesch_reading_ease)
|
||||
print("Flesch-Kincaid Grade Level:", flesch_kincaid_grade)
|
||||
```
|
||||
|
||||
### nltk 库
|
||||
|
||||
|
||||
|
||||
- **安装**:可以通过`pip install nltk`安装,同时可能还需要下载一些 nltk 的语料库资源。
|
||||
- **使用示例**
|
||||
|
||||
|
||||
|
||||
收起
|
||||
|
||||
python
|
||||
|
||||
```
|
||||
import nltk
|
||||
from nltk.tokenize import word_tokenize, sent_tokenize
|
||||
import nltk.data
|
||||
|
||||
nltk.download('punkt')
|
||||
|
||||
def flesch_kincaid_analysis(text):
|
||||
words = word_tokenize(text)
|
||||
sentences = sent_tokenize(text)
|
||||
syllables_per_word = lambda word: sum(1 for char in word if char in "aeiouAEIOU")
|
||||
total_syllables = sum(syllables_per_word(word) for word in words)
|
||||
total_words = len(words)
|
||||
total_sentences = len(sentences)
|
||||
|
||||
flesch_reading_ease = 206.835 - 1.015 * (total_words / total_sentences) - 84.6 * (total_syllables / total_words)
|
||||
flesch_kincaid_grade = 0.39 * (total_words / total_sentences) + 11.8 * (total_syllables / total_words) - 15.59
|
||||
|
||||
return flesch_reading_ease, flesch_kincaid_grade
|
||||
|
||||
text = "This is another sample text. It has more words and longer sentences to test the Flesch-Kincaid analysis."
|
||||
flesch_reading_ease, flesch_kincaid_grade = flesch_kincaid_analysis(text)
|
||||
|
||||
print("Flesch Reading Ease:", flesch_reading_ease)
|
||||
print("Flesch-Kincaid Grade Level:", flesch_kincaid_grade)
|
||||
```
|
||||
|
||||
|
||||
|
||||
quora.com
|
||||
|
||||
对于中国的学生,从小学4年级,到高中3年级, 阅读理解的文章适合分配给他们多少Flesch - Kincaid分值的文章
|
||||
|
||||
Flesch-Kincaid 分值对应的文本难度有其自身特点,以下是一个大致对应中国学生从小学四年级到高中三年级的 Flesch-Kincaid 分值范围及分析:
|
||||
|
||||
|
||||
|
||||
- **小学四年级**
|
||||
- **分值范围**:一般来说,Flesch-Kincaid 分值在 60-70 左右的文章可能比较适合小学四年级学生。
|
||||
- **分析**:这个阶段的学生正处于从简单的图文阅读向纯文字阅读过渡的时期,需要一定难度来提升阅读能力,但又不能过难。该分值范围的文章句子结构相对简单,词汇也多为常见基础词汇,能够帮助他们逐渐适应较为复杂的文本阅读,培养阅读兴趣和基本的理解能力。
|
||||
- **小学五年级到六年级**
|
||||
- **分值范围**:Flesch-Kincaid 分值在 50-65 之间的文章较为合适。
|
||||
- **分析**:学生的阅读能力在这一阶段有了进一步提升,能够理解更复杂一些的句子和稍多的词汇。这个分值范围的文章开始出现一些复合句、复杂句,词汇量也有所增加,可以帮助他们锻炼理解和分析能力,为初中阶段的阅读学习做准备。
|
||||
- **初中一年级到二年级**
|
||||
- **分值范围**:Flesch-Kincaid 分值在 40-55 之间比较适宜。
|
||||
- **分析**:初中学生的认知水平和语言能力有了较大提高,能够处理更具挑战性的文本。这一分值区间的文章在词汇和句子结构上更加复杂,还可能涉及一些修辞手法、文化背景等内容,有助于他们提升阅读理解的深度和广度,培养对不同类型文本的分析能力。
|
||||
- **初中三年级**
|
||||
- **分值范围**:Flesch-Kincaid 分值在 35-50 之间的文章较为匹配。
|
||||
- **分析**:初三学生面临中考,需要接触难度更高的阅读材料来提升应试能力和综合素养。这个分值的文章可能包含更多的专业词汇、长难句,以及更复杂的逻辑关系和主题思想,能够帮助他们适应中考阅读理解的难度要求,提高在有限时间内提取关键信息和理解文本主旨的能力。
|
||||
- **高中一年级到二年级**
|
||||
- **分值范围**:Flesch-Kincaid 分值在 30-45 之间的文章比较符合这一阶段学生的水平。
|
||||
- **分析**:高中学生的思维能力和语言理解能力进一步增强,需要阅读具有深度和广度的文章来拓展知识、提升思维品质。此分值范围的文章往往在词汇量、句子复杂度、文化内涵等方面都有较高要求,可能涉及文学作品、学术论文、时事评论等多种体裁,有助于他们培养批判性思维和对不同文化背景的理解能力。
|
||||
- **高中三年级**
|
||||
- **分值范围**:Flesch-Kincaid 分值在 25-40 之间的文章对高三学生来说是比较合适的挑战。
|
||||
- **分析**:高三学生即将面临高考,需要接触高难度的阅读文本以应对高考中的阅读理解和完形填空等题型。这样分值的文章可能具有很强的专业性、逻辑性和文化深度,词汇更加生僻,句子结构更为复杂,能够帮助他们提升在高强度考试压力下的阅读速度和理解准确性,培养对复杂文本的综合分析和解读能力。
|
||||
|
||||
quora.com
|
||||
|
||||
请给一个分支大概65分的文章例子
|
||||
|
||||
理解问题
|
||||
|
||||
搜索网页
|
||||
|
||||
请给一个分支大概65分的文章例子
|
||||
|
||||
Flesch-Kincaid分值65分的文章例子
|
||||
|
||||
找到 5 个搜索来源
|
||||
|
||||
[
|
||||
|
||||
外贸网站运营中,如何提升网站内容的可读性?_手机搜狐网
|
||||
|
||||
搜狐网
|
||||
|
||||
1
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
](https://m.sohu.com/a/708020596_121769793/)
|
||||
|
||||
[
|
||||
|
||||
人教版七年级上思想品德教材的可读性研究的中期报告.docx - 道客巴巴
|
||||
|
||||
道客巴巴
|
||||
|
||||
2
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
](https://m.doc88.com/p-19239223168762.html)
|
||||
|
||||
[
|
||||
|
||||
ACT考试-从文本难度分析ACT考试阅读难度等级(一)-Sandy - 360文档中心
|
||||
|
||||
360文档中心
|
||||
|
||||
3
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
](https://m.360docs.net/doc/2d14756119.html)
|
||||
|
||||
[
|
||||
|
||||
一次自我觉察——A Christmas Carol读后感 - 日记 - 豆瓣
|
||||
|
||||
豆瓣
|
||||
|
||||
4
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
](https://m.douban.com/note/843403656/)
|
||||
|
||||
[
|
||||
|
||||
我院教工第三党支部联合语言与通识教育中心共同组织开展教研活动 - 党建新闻 - 华南师范大学国际商学院
|
||||
|
||||
华南师范大学国际商学院
|
||||
|
||||
5
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
](http://ibc.scnu.edu.cn/a/20240711/2451.html)
|
||||
|
||||
以下是一篇 Flesch-Kincaid 分值大概在 65 分左右的文章例子:
|
||||
|
||||
|
||||
|
||||
It was a sunny day. I went to the park with my friends. We took a football and a Frisbee with us. When we got to the park, there were already a lot of people there. Some were flying kites, some were having a picnic, and some were just taking a walk.
|
||||
|
||||
|
||||
|
||||
We found a nice spot on the grass and started to play football. We kicked the ball around, passing it to each other. It was so much fun. After a while, we got a little tired and decided to play Frisbee instead. The Frisbee flew high in the air and we ran to catch it.
|
||||
|
||||
|
||||
|
||||
Later, we sat down and had some snacks that we brought. We talked and laughed, enjoying the beautiful day. As the sun started to set, we packed up our things and went home. It was a really great day at the park.
|
||||
|
||||
|
||||
|
||||
这篇文章句子结构较为简单,多为简单句和并列句,用词也比较基础和常见,符合 Flesch-Kincaid 分值 65 分左右的文本特点,属于比较容易理解的标准难度文本。当然,如果用相关工具具体计算,可能会因统计方式等因素有一定波动,但大致在这个分值范围附近。
|
||||
|
||||
quora.com
|
||||
|
||||
再来一个分值30的
|
||||
|
||||
在科学的浩瀚宇宙中,量子力学宛如一颗璀璨却神秘莫测的星辰,散发着令人着迷又困惑的光芒。量子力学,作为描述微观世界物质运动规律的理论,其诞生彻底颠覆了人们对传统物理的认知。
|
||||
|
||||
|
||||
|
||||
回溯到 20 世纪初,经典物理学在解释黑体辐射、光电效应等微观现象时遭遇了前所未有的困境。普朗克为解决黑体辐射问题,大胆提出了能量量子化假说,犹如在黑暗中点亮了第一盏灯,为量子力学的发展拉开了序幕。随后,爱因斯坦基于普朗克的理论,成功解释了光电效应,进一步证实了光的量子特性,光不仅具有波动性,还具有粒子性,这种波粒二象性的概念打破了经典物理中对光的单一认知。
|
||||
|
||||
|
||||
|
||||
而玻尔的原子模型则是量子力学发展历程中的又一重要里程碑。他将量子化概念引入原子结构,解释了氢原子光谱的规律,使得人们对原子内部的奥秘有了更深入的理解。但这仅仅是个开始,随着研究的深入,更多令人匪夷所思的现象接踵而至。例如,量子纠缠现象,当两个或多个粒子处于纠缠态时,无论它们相隔多远,对其中一个粒子的测量会瞬间影响到其他粒子的状态,这种超距作用仿佛打破了空间的限制,违背了我们日常的直觉。
|
||||
|
||||
|
||||
|
||||
薛定谔方程的出现,为量子力学提供了一个强大的数学工具,它能够描述微观粒子的波函数随时间的演化,然而波函数的概率诠释又引发了诸多争议。在量子力学中,粒子的状态不再是确定的,而是以概率的形式存在,只有在进行测量时,波函数才会坍缩到一个确定的本征态,这一观点与经典物理中确定性的世界观大相径庭。
|
||||
|
||||
|
||||
|
||||
海森堡的不确定性原理同样给人们带来了巨大的冲击。它表明,我们无法同时精确地测量一个粒子的位置和动量,对其中一个量的测量精度越高,对另一个量的测量精度就越低,这似乎在微观世界中设置了一道不可逾越的认知界限。
|
||||
|
||||
|
||||
|
||||
量子力学的发展历程充满了挑战与突破,它不断地挑战着人类的思维极限,也为现代科技的发展奠定了坚实的基础。从半导体技术到量子计算,从激光到核磁共振,量子力学的应用无处不在,深刻地改变了我们的生活。但与此同时,它所蕴含的诸多未解之谜,如量子测量问题、量子引力的统一等,仍然吸引着无数科学家不断探索前行,试图揭开微观世界那层神秘的面纱 ,去探寻宇宙最本质的奥秘。
|
||||
|
||||
quora.com
|
||||
|
||||
我的意思是,再来一个 Flesch-Kincaid分值30左右的 英文例子
|
||||
|
||||
基于 5 个搜索来源
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
以下是一篇 Flesch-Kincaid 分值大概在 30 左右的英文文章例子:
|
||||
|
||||
|
||||
|
||||
The concept of artificial intelligence has been a fascinating subject of research and development for decades. AI, as it is commonly known, refers to the simulation of human intelligence in machines that are programmed to think and learn like humans.
|
||||
|
||||
|
||||
|
||||
One of the key areas of AI is machine learning. It enables computers to analyze and interpret vast amounts of data, identifying patterns and making predictions based on that data. For example, in the field of healthcare, machine learning algorithms can analyze medical records to detect diseases at an early stage or predict patient outcomes.
|
||||
|
||||
|
||||
|
||||
Another important aspect is natural language processing (NLP). NLP allows machines to understand, interpret, and generate human language. This is used in applications like voice assistants, where you can ask questions and receive spoken responses. Chatbots are also a product of NLP, capable of having conversations with users to provide information or assistance.
|
||||
|
||||
|
||||
|
||||
AI has also made significant strides in computer vision. Machines can now recognize and interpret images and videos, which has numerous applications in security, autonomous vehicles, and even in retail for analyzing customer behavior.
|
||||
|
||||
|
||||
|
||||
However, the development of AI also brings about various challenges and ethical considerations. Issues such as data privacy, bias in algorithms, and the potential impact on employment are being widely debated. As AI continues to evolve, it is crucial that we address these concerns to ensure its responsible and beneficial use.
|
||||
|
||||
|
||||
|
||||
Overall, artificial intelligence is a rapidly advancing field with the potential to revolutionize many aspects of our lives, but it requires careful management and regulation to realize its full potential while minimizing risks.
|
||||
|
||||
除了Flesch-Kincaid分值,还有哪些英文文章可读性评估方法?
|
||||
|
||||
除了 Flesch - Kincaid 分值外,以下是一些常见的英文文章可读性评估方法:
|
||||
|
||||
### 可读性公式类
|
||||
|
||||
|
||||
|
||||
- **ARI(Automated Readability Index)**
|
||||
- **计算方法**:主要基于单词平均长度和句子平均长度来计算。统计文章中字符数、单词数和句子数,通过特定公式 ARI = 4.71×(字符数 / 单词数)+0.5×(单词数 / 句子数)-21.43 得出分值。
|
||||
- **特点**:较为注重文本的基本元素统计,计算相对简单直接,能快速反映出文章在词汇和句子长度方面的难度。
|
||||
- **Coleman-Liau Index**
|
||||
- **计算方法**:通过统计文章中的字母数和句子数来衡量可读性。公式为 CLI = 0.0588×L - 0.296×S - 15.8,其中 L 是每 100 个单词中的字母数,S 是每 100 个单词中的句子数。
|
||||
- **特点**:计算时考虑了字母数量,对于不同词汇丰富度的文本区分度较好,能在一定程度上反映词汇的复杂程度对可读性的影响。
|
||||
- **SMOG(Simple Measure of Gobbledygook)**
|
||||
- **计算方法**:主要统计文章中多音节词的数量。先数出文章中每 30 个句子里的多音节词数量,然后通过公式 SMOG = √(多音节词数量 ×30 / 句子数)+3 得出分值。
|
||||
- **特点**:重点关注多音节词,对于判断文本中复杂词汇的密集程度较为有效,适用于评估学术或专业领域文本的可读性。
|
||||
|
||||
### 基于词汇和语法分析类
|
||||
|
||||
|
||||
|
||||
- **词汇频率分析**
|
||||
- **方法**:借助词频统计工具,分析文章中不同词汇的出现频率。常用词汇列表如 CEFR(欧洲共同语言参考框架)词汇表、General Service List 等,将文章词汇与这些标准词汇表对比,统计不同等级词汇的占比。
|
||||
- **特点**:能直观了解文章词汇的难易分布,若高级词汇占比高,通常可读性相对较低。
|
||||
- **语法复杂度分析**
|
||||
- **方法**:分析句子结构的复杂性,如句子的嵌套层数、从句的使用频率、非谓语动词的使用情况等。还可以统计不同语法结构的多样性,结构越复杂、种类越多,可能可读性越低。
|
||||
- **特点**:从语法角度深入评估文本难度,对于理解文本的语言组织和逻辑关系的难度有重要参考价值。
|
||||
|
||||
### 基于语篇和语义分析类
|
||||
|
||||
|
||||
|
||||
- **连贯性和衔接性分析**
|
||||
- **方法**:考察文章中句子之间、段落之间的逻辑关系是否清晰,是否使用了恰当的衔接手段,如连词、代词、重复词汇等。评估文章的整体结构是否合理,主题是否明确,论述是否有条理。
|
||||
- **特点**:从整体语篇层面评估可读性,关注文本的组织和逻辑连贯性,对于判断文章的整体质量和理解难度至关重要。
|
||||
- **语义密度分析**
|
||||
- **方法**:分析文章中单位篇幅内所包含的信息量和概念的复杂程度。通过计算特定领域术语、抽象概念的出现频率等指标来衡量。
|
||||
- **特点**:能反映文章内容的深度和复杂度,对于评估专业文献、学术论文等具有较高信息量的文本可读性很有帮助。
|
||||
|
||||
### 基于读者反馈和测试类
|
||||
|
||||
|
||||
|
||||
- **问卷调查法**
|
||||
- **方法**:设计针对文章可读性的问卷,让读者对文章的理解难度、兴趣度、清晰度等方面进行打分或评价。可以设置具体问题,如 “你是否容易理解文章的主要内容”“文章中是否有让你感到困惑的词汇或句子” 等。
|
||||
- **特点**:直接获取读者的主观感受,能综合反映不同读者群体对文章可读性的看法,但结果可能受读者个体差异和主观因素影响。
|
||||
- **阅读理解测试法**
|
||||
- **方法**:让读者阅读文章后进行相关的阅读理解测试,如回答问题、总结内容、进行推理判断等。根据读者的答题正确率来评估文章的可读性。
|
||||
- **特点**:通过实际测试能较为客观地反映读者对文章的理解程度,结果具有一定的量化指标,但测试题目设计的合理性会影响评估结果。
|
||||
|
||||
Flesch - Kincaid 分值和其他可读性公式类方法有何关联?
|
||||
|
||||
除了公式类方法,还有哪些英文文章可读性评估方法?
|
||||
|
||||
如何使用这些可读性评估方法来提高英文文章的可读性?
|
||||
|
||||
AI 编程
|
||||
|
||||
图像生成
|
||||
|
||||
帮我写作
|
||||
|
||||
AI 搜索
|
||||
|
||||
AI 阅读
|
||||
|
||||
学术搜索
|
||||
|
||||
解题答疑
|
||||
|
||||
更多
|
||||
|
||||
quora.com
|
||||
|
||||

|
||||
|
||||
豆包
|
||||
|
||||
新对话
|
||||
|
||||
[
|
||||
|
||||
AI 搜索
|
||||
|
||||
](https://www.doubao.com/chat/search)
|
||||
|
||||
[
|
||||
|
||||
帮我写作
|
||||
|
||||
](https://www.doubao.com/chat/write)
|
||||
|
||||
[
|
||||
|
||||
图像生成
|
||||
|
||||
](https://www.doubao.com/chat/create-image)
|
||||
|
||||
[
|
||||
|
||||
AI 阅读
|
||||
|
||||
](https://www.doubao.com/chat/chat-with-doc)
|
||||
|
||||
[
|
||||
|
||||
AI 编程
|
||||
|
||||
](https://www.doubao.com/chat/coding)
|
||||
|
||||
语音通话
|
||||
|
||||
[
|
||||
|
||||
AI 看网站
|
||||
|
||||
有更新
|
||||
|
||||
|
||||
|
||||
](https://www.doubao.com/chat/pc-ai-guidance)
|
||||
|
||||
最近对话
|
||||
|
||||
[
|
||||
|
||||
寻找英文短文
|
||||
|
||||
](https://www.doubao.com/chat/1145749456022018)
|
||||
|
||||
[
|
||||
|
||||
总结 n8n 页面
|
||||
|
||||
](https://www.doubao.com/chat/1127008857215746)
|
||||
|
||||
[
|
||||
|
||||
Microk8s 中 Deployment 更新及 Pod 体现
|
||||
|
||||
](https://www.doubao.com/chat/1128749143074050)
|
||||
|
||||
[
|
||||
|
||||
在 LazyVim 中搜索单词
|
||||
|
||||
](https://www.doubao.com/chat/1066513245694210)
|
||||
|
||||
[
|
||||
|
||||
解释向量数据库
|
||||
|
||||
](https://www.doubao.com/chat/1130887125227522)
|
||||
|
||||
[
|
||||
|
||||
查看全部...
|
||||
|
||||
](https://www.doubao.com/chat/thread/list)
|
||||
|
||||
书签
|
||||
|
||||
- 
|
||||
|
||||
Marscode
|
||||
|
||||
- 
|
||||
|
||||
知乎
|
||||
|
||||
- 
|
||||
|
||||
抖音
|
||||
|
||||
- 
|
||||
|
||||
番茄小说
|
||||
|
||||
- 
|
||||
|
||||
即梦 AI绘画
|
||||
|
||||
- 
|
||||
|
||||
BiliBili
|
||||
|
||||
- 
|
||||
|
||||
今日头条
|
||||
|
||||
|
||||
[
|
||||
|
||||
AI 云盘
|
||||
|
||||
](https://www.doubao.com/chat/drive/)
|
||||
|
||||
我的智能体
|
||||
|
||||
[
|
||||
|
||||
收藏夹
|
||||
|
||||
](https://www.doubao.com/chat/collection)
|
||||
|
||||
我的意思是,再来一个 Flesch-Kincaid分值30左右的 英文例子
|
||||
BIN
Pasted image 20250204021453.png
Normal file
BIN
Pasted image 20250204021453.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 85 KiB |
BIN
Pasted image 20250204022601.png
Normal file
BIN
Pasted image 20250204022601.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 96 KiB |
BIN
Pasted image 20250222113205.png
Normal file
BIN
Pasted image 20250222113205.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 52 KiB |
BIN
Pasted image 20250222115616.png
Normal file
BIN
Pasted image 20250222115616.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 26 KiB |
2
avante/neo-vim_ai 编程辅助插件-avante_扩展使用指南.md
Normal file
2
avante/neo-vim_ai 编程辅助插件-avante_扩展使用指南.md
Normal file
@ -0,0 +1,2 @@
|
||||
|
||||
为什么用neo-vim 来写代码,这里就不多讲了, 懂得都懂. 这段时间. cursor特别火, 我也试试了, 的确好用, 但是试用期结束以后, 我也懒得邮箱换来换去, 就想着找一款在nvim上能用的AI扩展, 我呢,目前用的是Lazyvim, 配置起来比较简单.
|
||||
277
ccxt-go中文文档, 豆包生成.md
Normal file
277
ccxt-go中文文档, 豆包生成.md
Normal file
@ -0,0 +1,277 @@
|
||||
# ccxt-go 中文文档
|
||||
|
||||
## 1. 简介
|
||||
|
||||
ccxt-go 是将 CCXT(CryptoCurrency eXchange Trading)交换库从原始 JavaScript 源代码转换为 Go(Golang)语言的版本。CCXT 库是一个涵盖众多加密货币交易所的集合,每个交易所类都实现了特定加密货币交易所的公共和私有 API。所有交易所都派生自基础交易所类,并共享一组通用方法。通过 ccxt-go,开发者能够使用 Go 语言通过统一的 API 与超过 100 个加密货币交易所进行交互,实现获取市场数据、交易操作、套利等功能。
|
||||
|
||||
## 2. 特点
|
||||
|
||||
**多交易所支持**:通过一个统一的 API 支持 100 多个加密货币交易所,极大地便利了需要同时与多个交易所进行交互的应用开发。无论是进行市场数据的综合分析,还是实施跨交易所的套利策略,亦或是构建一个面向多平台的加密货币交易终端,都能轻松实现。
|
||||
|
||||
**完整 API 实现**:完全实现了公共和私人 API。公共 API 可用于获取各种市场数据,例如市场行情(ticker),它能返回指定交易对当前的价格、成交量等基本市场信息;订单簿(order book),可获取买卖双方不同价格档位的挂单数量和金额,清晰展示市场供需情况;交易历史(trades),包含了一定时间范围内指定交易对的所有成交记录,对分析市场交易活跃度和价格走势有重要意义;K 线数据(ohlcv),以特定时间周期(如 1 分钟、1 小时、1 天等)展示开盘价、最高价、最低价、收盘价和成交量,广泛应用于技术分析。私人 API 则用于交易操作,如创建订单(create order),可根据市场情况和交易策略创建限价单、市价单等不同类型的订单;取消订单(cancel order),当市场情况发生变化或原订单策略不再适用时,及时撤销未成交订单;查询账户余额(fetch balance),准确获取用户在交易所账户中的各类资产余额,方便资金管理和交易决策。这些功能满足了开发者在加密货币交易领域的各种需求。
|
||||
|
||||
**标准化数据**:提供了可选的标准化数据,方便进行跨交易所或跨货币的分析和套利操作。不同交易所的数据格式往往存在差异,而 ccxt-go 对数据进行标准化处理后,开发者可以更便捷地对来自不同交易所的数据进行统一分析和处理,无需花费大量精力去适配每个交易所独特的数据格式。例如,在进行跨交易所套利时,能快速对比不同平台同一交易对的价格差异,而无需担心数据格式不一致带来的困扰。
|
||||
|
||||
## 3. 要求
|
||||
|
||||
使用 ccxt-go 需要确保开发环境中安装的 Go 版本为 >= 1.13 。较新的 Go 版本通常带来了性能优化、新特性支持以及对一些已知问题的修复,能够更好地与 ccxt-go 库协同工作,保证程序的稳定性和功能性。例如,Go 1.13 版本增强了对错误处理的改进,使得 ccxt-go 在处理交易所 API 返回的错误信息时能更加精准和友好,提升了程序的健壮性。
|
||||
|
||||
## 4. 安装
|
||||
|
||||
你可以使用以下命令进行安装:
|
||||
|
||||
|
||||
|
||||
```
|
||||
go get https://github.com/prompt-cash/ccxt-go
|
||||
```
|
||||
|
||||
该命令会从指定的 GitHub 仓库下载 ccxt-go 库及其依赖,并将其安装到你的 Go 项目环境中,以便在项目中引入和使用。安装完成后,你可以在项目代码中通过`import`语句引入 ccxt-go 库,开始使用其提供的功能。例如:
|
||||
|
||||
|
||||
|
||||
```
|
||||
import "github.com/prompt-cash/ccxt-go/ccxt"
|
||||
```
|
||||
|
||||
## 5. 使用示例
|
||||
|
||||
### 5.1 初始化交易所实例
|
||||
|
||||
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
|
||||
"fmt"
|
||||
|
||||
"github.com/prompt-cash/ccxt-go/ccxt"
|
||||
|
||||
)
|
||||
|
||||
func main() {
|
||||
|
||||
// 初始化币安交易所实例
|
||||
|
||||
binance := ccxt.NewBinance()
|
||||
|
||||
// 加载市场数据
|
||||
|
||||
err := binance.LoadMarkets()
|
||||
|
||||
if err != nil {
|
||||
|
||||
fmt.Println("加载市场数据错误:", err)
|
||||
|
||||
return
|
||||
|
||||
}
|
||||
|
||||
// 输出支持的交易对
|
||||
|
||||
for symbol := range binance.Markets {
|
||||
|
||||
fmt.Println(symbol)
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
在上述示例中,首先通过`ccxt.NewBinance()`创建了一个币安交易所的实例`binance`。`LoadMarkets`方法用于加载该交易所的市场数据,这一过程会获取交易所支持的所有交易对、交易规则以及相关市场参数等信息。如果加载过程中出现错误,会打印错误信息并终止程序。最后,通过遍历`binance.Markets`输出该交易所支持的所有交易对。在实际应用中,初始化交易所实例并加载市场数据是后续进行各种交易操作和数据获取的基础,比如在构建一个加密货币交易机器人时,第一步就需要准确加载所支持交易所的市场数据,以便后续根据市场情况制定交易策略。
|
||||
|
||||
### 5.2 获取行情数据
|
||||
|
||||
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
|
||||
"fmt"
|
||||
|
||||
"github.com/prompt-cash/ccxt-go/ccxt"
|
||||
|
||||
"time"
|
||||
|
||||
)
|
||||
|
||||
func main() {
|
||||
|
||||
binance := ccxt.NewBinance()
|
||||
|
||||
err := binance.LoadMarkets()
|
||||
|
||||
if err != nil {
|
||||
|
||||
fmt.Println("加载市场数据错误:", err)
|
||||
|
||||
return
|
||||
|
||||
}
|
||||
|
||||
symbol := "BTC/USDT"
|
||||
|
||||
// 获取订单簿数据
|
||||
|
||||
orderBook, err := binance.FetchOrderBook(symbol, 10)
|
||||
|
||||
if err != nil {
|
||||
|
||||
fmt.Println("获取订单簿错误:", err)
|
||||
|
||||
return
|
||||
|
||||
}
|
||||
|
||||
fmt.Println("订单簿数据:", orderBook)
|
||||
|
||||
// 获取公开成交数据
|
||||
|
||||
trades, err := binance.FetchTrades(symbol, 0, 5)
|
||||
|
||||
if err != nil {
|
||||
|
||||
fmt.Println("获取公开成交数据错误:", err)
|
||||
|
||||
return
|
||||
|
||||
}
|
||||
|
||||
fmt.Println("公开成交数据:", trades)
|
||||
|
||||
// 获取ticker数据
|
||||
|
||||
ticker, err := binance.FetchTicker(symbol)
|
||||
|
||||
if err != nil {
|
||||
|
||||
fmt.Println("获取ticker数据错误:", err)
|
||||
|
||||
return
|
||||
|
||||
}
|
||||
|
||||
fmt.Println("ticker数据:", ticker)
|
||||
|
||||
// 获取K线数据
|
||||
|
||||
ohlcv, err := binance.FetchOHLCV(symbol, "1d")
|
||||
|
||||
if err != nil {
|
||||
|
||||
fmt.Println("获取K线数据错误:", err)
|
||||
|
||||
return
|
||||
|
||||
}
|
||||
|
||||
fmt.Println("K线数据:", ohlcv)
|
||||
|
||||
// 每次请求之间添加延迟,避免触发速率限制
|
||||
|
||||
time.Sleep(500 \* time.Millisecond)
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
此示例展示了如何使用 ccxt-go 获取不同类型的行情数据。针对指定的交易对(如 “BTC/USDT”),`FetchOrderBook`方法用于获取订单簿数据,其中第二个参数`10`表示获取 10 档盘口数据,即买卖双方各 10 个价格档位的挂单信息,通过分析这些数据可以了解市场的深度和潜在的价格压力。`FetchTrades`方法用于获取公开成交数据,第一个参数为交易对,第二个参数`0`表示从最新的成交记录开始获取,第三个参数`5`表示限制返回 5 条成交记录,这些成交数据能直观反映市场近期的交易活跃度和价格变动情况。`FetchTicker`方法获取 ticker 数据,返回的 ticker 包含了当前交易对的最新价格、24 小时最高价、最低价、成交量等关键市场信息,是快速了解市场行情的重要途径。`FetchOHLCV`方法获取 K 线数据,第二个参数`"1d"`表示获取 1 天的 K 线数据,K 线数据在技术分析中广泛应用,通过分析不同时间周期的 K 线形态可以预测市场价格走势。在每次请求之间添加了 500 毫秒的延迟,以避免因频繁请求触发交易所的速率限制。在量化交易场景中,获取行情数据是实时监测市场变化、制定交易策略的关键环节。例如,通过实时获取订单簿数据和 ticker 数据,结合一定的算法模型,可以及时捕捉市场价格波动,发现套利机会并执行交易操作。
|
||||
|
||||
### 5.3 交易操作(需要谨慎使用真实 API 密钥)
|
||||
|
||||
|
||||
|
||||
```
|
||||
package main
|
||||
|
||||
import (
|
||||
|
||||
"fmt"
|
||||
|
||||
"github.com/prompt-cash/ccxt-go/ccxt"
|
||||
|
||||
)
|
||||
|
||||
func main() {
|
||||
|
||||
apiKey := "YOUR\_API\_KEY"
|
||||
|
||||
secret := "YOUR\_SECRET\_KEY"
|
||||
|
||||
binance := ccxt.NewBinance()
|
||||
|
||||
binance.ApiKey = apiKey
|
||||
|
||||
binance.Secret = secret
|
||||
|
||||
// 资产查询
|
||||
|
||||
balance, err := binance.FetchBalance()
|
||||
|
||||
if err != nil {
|
||||
|
||||
fmt.Println("资产查询错误:", err)
|
||||
|
||||
return
|
||||
|
||||
}
|
||||
|
||||
fmt.Println("账户余额:", balance)
|
||||
|
||||
symbol := "BTC/USDT"
|
||||
|
||||
amount := 0.001
|
||||
|
||||
price := 25000.0
|
||||
|
||||
// 限价买单
|
||||
|
||||
order, err := binance.CreateLimitBuyOrder(symbol, amount, price)
|
||||
|
||||
if err != nil {
|
||||
|
||||
fmt.Println("创建限价买单错误:", err)
|
||||
|
||||
return
|
||||
|
||||
}
|
||||
|
||||
fmt.Println("创建的限价买单:", order)
|
||||
|
||||
// 撤单(假设获取到订单ID后进行撤单操作,这里仅为示例)
|
||||
|
||||
orderId := order\["id"].(string)
|
||||
|
||||
err = binance.CancelOrder(orderId, symbol)
|
||||
|
||||
if err != nil {
|
||||
|
||||
fmt.Println("撤单错误:", err)
|
||||
|
||||
return
|
||||
|
||||
}
|
||||
|
||||
fmt.Println("订单已撤销")
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
在进行实际交易操作时,务必谨慎使用真实的 API 密钥。此示例中,首先设置了币安交易所的 API 密钥和密钥对(`apiKey`和`secret`),这两个密钥是访问交易所私人 API 的凭证,用于验证用户身份和授权交易操作。然后通过`FetchBalance`方法查询账户余额,该方法返回的`balance`包含了用户在交易所账户中的各类资产余额,如比特币(BTC)、以太坊(ETH)、稳定币(USDT 等)的数量,方便用户了解自己的资金状况,为后续交易决策提供依据。接着,尝试创建一个限价买单(`CreateLimitBuyOrder`),指定交易对(“BTC/USDT”)、购买数量(0.001)和价格(25000.0)。限价单是指用户指定一个期望的买入价格,当市场价格达到或优于该价格时,订单将被执行。在成功创建订单后,获取订单 ID 并尝试使用`CancelOrder`方法撤销该订单,`CancelOrder`方法需要传入订单 ID 和交易对,用于撤销指定的未成交订单。在实际应用中,交易操作涉及资金的变动,必须严格按照业务逻辑和风险控制要求进行。例如,在构建一个自动化交易系统时,需要对交易操作进行严格的验证和监控,确保每一笔交易都符合预设的交易策略和风险承受能力。同时,要注意对 API 密钥的安全管理,防止密钥泄露导致资金损失。
|
||||
|
||||
## 6. 注意事项
|
||||
|
||||
**版本兼容性**:由于 ccxt-go 仍处于不断发展和完善的阶段,可能存在一些功能尚未完全实现或部分功能在不同版本间存在兼容性问题。在使用过程中,建议密切关注官方仓库的更新说明,及时更新到最新版本以获取更好的功能支持和问题修复。例如,某些早期版本在处理特定交易所的 API 请求时可能存在数据解析错误,通过更新到最新版本可以解决这些问题,确保程序的正常运行。
|
||||
|
||||
**速率限制**:不同的加密货币交易所对 API 请求的速率限制各不相同。在编写程序时,务必注意合理控制请求频率,避免因频繁请求触发交易所的速率限制,导致请求失败或账户被封禁。如在获取行情数据的示例中,通过在每次请求之间添加适当的延迟来避免此类问题。一些交易所可能限制每秒或每分钟的请求次数,开发者需要根据交易所的具体限制规则,结合自己的业务需求,合理调整请求频率。例如,可以采用队列机制,将请求按顺序排队发送,确保在不超过速率限制的前提下,尽可能高效地获取数据。
|
||||
|
||||
**安全风险**:在进行涉及交易操作的功能开发时,要特别注意 API 密钥等敏感信息的安全保护。避免将密钥硬编码在公开的代码仓库或不安全的环境中,建议采用安全的密钥管理方式,如环境变量、配置文件加密等,以防止密钥泄露带来的资金损失风险。如果密钥泄露,恶意用户可能会利用该密钥在交易所进行未经授权的交易,导致用户资金受损。因此,安全的密钥管理至关重要,例如使用环境变量存储密钥时,在部署程序时可以通过服务器的环境变量配置进行设置,避免在代码中直接暴露密钥。
|
||||
|
||||
## 7. 更多信息
|
||||
|
||||
**官方仓库**:ccxt-go 的官方 GitHub 仓库为[https://github.com/prompt-cash/ccxt-go](https://github.com/prompt-cash/ccxt-go) ,你可以在该仓库中获取最新的代码、提交问题反馈、查看其他开发者的贡献以及参与项目讨论。在官方仓库中,不仅能获取到最新版本的 ccxt-go 库代码,还能通过查看提交记录了解库的功能演进和问题修复情况。同时,提交问题反馈有助于开发者社区及时发现和解决库中存在的问题,参与项目讨论则能与其他开发者交流经验,共同推动 ccxt-go 的发展。
|
||||
|
||||
**测试用例**:在仓库中的`ccxt_test.go`文件包含了许多测试用例,通过查看这些测试用例可以深入了解 ccxt-go 的各种功能的使用方式和预期输出,有助于开发者更快地掌握和使用该库进行项目开发。例如,测试用例中可能包含对不同交易所初始化、行情数据获取、交易操作等功能的测试,通过分析这些测试代码,可以学习到如何正确调用 ccxt-go 的各个方法,以及这些方法在不同情况下的返回值和可能出现的错误,从而更好地应用于实际项目开发中。
|
||||
107
ccxt.md
Normal file
107
ccxt.md
Normal file
@ -0,0 +1,107 @@
|
||||
### 类与接口
|
||||
|
||||
#### Exchange
|
||||
- **描述**: `Exchange` 是一个表示交易所的基本结构体。它包含了交易所的名称、API密钥等信息,并实现了一系列用于交互的方法。
|
||||
|
||||
#### OKXExchange(示例)
|
||||
- **描述**: `OKXExchange` 是继承自 `Exchange` 的一个具体实现,专门为OKX交易所提供API调用功能。
|
||||
|
||||
### 方法说明
|
||||
|
||||
#### Exchange 类中的公共方法
|
||||
|
||||
1. **NewExchange**
|
||||
- **整体说明**: 创建并返回一个新的 `Exchange` 实例。
|
||||
- **方法签名**: `func NewExchange(config Config) (*Exchange, error)`
|
||||
- **入参**:
|
||||
- `config`: 用于配置交易所信息的结构体。
|
||||
|
||||
2. **GetTicker**
|
||||
- **整体说明**: 获取当前市场的最新价格。
|
||||
- **方法签名**: `func (e *Exchange) GetTicker(symbol string) (*Ticker, error)`
|
||||
- **入参**:
|
||||
- `symbol`: 表示货币对,如 "BTC/USDT"。
|
||||
|
||||
3. **PlaceOrder**
|
||||
- **整体说明**: 在交易所下单。
|
||||
- **方法签名**: `func (e *Exchange) PlaceOrder(order Order) (*OrderResponse, error)`
|
||||
- **入参**:
|
||||
- `order`: 包含订单信息的结构体,如买卖类型、价格等。
|
||||
|
||||
#### OKXExchange 类中的公共方法
|
||||
|
||||
1. **FetchOHLCV**
|
||||
- **整体说明**: 从OKX交易所获取K线数据。
|
||||
- **方法签名**: `func (o *OKXExchange) FetchOHLCV(symbol string, interval time.Duration, since, limit int64) ([]OHLCV, error)`
|
||||
- **入参**:
|
||||
- `symbol`: 货币对,如 "BTC/USDT"。
|
||||
- `interval`: K线周期,如1分钟、5分钟等。
|
||||
- `since`: 从该时间戳开始获取数据。
|
||||
- `limit`: 获取的K线数量限制。
|
||||
|
||||
### 使用示例
|
||||
|
||||
以下是一个使用 `Exchange` 和 `OKXExchange` 的示例代码:
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"time"
|
||||
)
|
||||
|
||||
func main() {
|
||||
// 创建配置结构体,填入必要信息
|
||||
config := Config{
|
||||
APIKey: "your_api_key",
|
||||
SecretKey: "your_secret_key",
|
||||
BaseURL: "https://www.okx.com/api/v5/",
|
||||
EnableRateLimit: true,
|
||||
}
|
||||
|
||||
// 使用NewExchange创建一个新的交易所实例
|
||||
exchange, err := NewExchange(config)
|
||||
if err != nil {
|
||||
fmt.Println("Error creating exchange:", err)
|
||||
return
|
||||
}
|
||||
|
||||
// 获取BTC/USDT的最新价格
|
||||
ticker, err := exchange.GetTicker("BTC/USDT")
|
||||
if err != nil {
|
||||
fmt.Println("Error fetching ticker:", err)
|
||||
return
|
||||
}
|
||||
fmt.Printf("Latest Ticker: %+v\n", ticker)
|
||||
|
||||
// 创建一个OKXExchange实例
|
||||
okxExchange := &OKXExchange{
|
||||
Exchange: exchange,
|
||||
}
|
||||
|
||||
// 获取BTC/USDT的1分钟K线数据
|
||||
ohlcv, err := okxExchange.FetchOHLCV("BTC/USDT", 1*time.Minute, 0, 10)
|
||||
if err != nil {
|
||||
fmt.Println("Error fetching OHLCV:", err)
|
||||
return
|
||||
}
|
||||
fmt.Printf("Latest OHLCV: %+v\n", ohlcv)
|
||||
|
||||
// 下单示例(假设Order结构体已定义)
|
||||
order := Order{
|
||||
Symbol: "BTC/USDT",
|
||||
Type: "buy",
|
||||
Price: 50000,
|
||||
Amount: 0.01,
|
||||
}
|
||||
response, err := exchange.PlaceOrder(order)
|
||||
if err != nil {
|
||||
fmt.Println("Error placing order:", err)
|
||||
return
|
||||
}
|
||||
fmt.Printf("Order Response: %+v\n", response)
|
||||
}
|
||||
```
|
||||
|
||||
在这个示例中,我们展示了如何创建交易所实例、获取最新价格和K线数据,并下单。请根据实际情况调整API密钥和其他配置信息。
|
||||
250
core/go_wire 循环依赖.md
Normal file
250
core/go_wire 循环依赖.md
Normal file
@ -0,0 +1,250 @@
|
||||
|
||||
😯: go里的wire模块, 安装后, 可以使用wire命令, 来生成依赖注入的代码, 具体怎么使用,能否结合一个使用场景的例子,演示一下
|
||||
|
||||
😐: Go 里的 wire 模块是一个用于依赖注入(DI,Dependency Injection)的工具,可以帮助我们自动生成依赖注入的代码,从而减少手动编写的样板代码。使用 wire 可以提高代码的模块化,减少手动配置的错误。
|
||||
|
||||
|
||||
|
||||
**安装 wire**
|
||||
|
||||
|
||||
|
||||
首先,你需要安装 wire 工具:
|
||||
|
||||
```
|
||||
go install github.com/google/wire/cmd/wire@latest
|
||||
```
|
||||
|
||||
**使用 wire 的基本步骤**
|
||||
|
||||
1. **定义接口和实现**:在你的项目中定义需要依赖注入的接口和结构体。
|
||||
|
||||
2. **创建 Wire Provider Function**:提供函数用来创建对象。
|
||||
|
||||
3. **创建 Wire Injector Function**:使用 wire 提供的功能来自动生成依赖注入代码。
|
||||
|
||||
4. **运行 wire 命令**:生成依赖注入代码。
|
||||
|
||||
|
||||
|
||||
**示例场景**
|
||||
|
||||
|
||||
|
||||
假设你有一个 web 服务,需要使用一个 UserService,而 UserService 又依赖于一个 UserRepository,我们希望通过 wire 来自动管理这些依赖关系。
|
||||
|
||||
|
||||
|
||||
**步骤 1:定义接口和实现**
|
||||
|
||||
|
||||
|
||||
首先,定义 UserRepository 和 UserService。
|
||||
|
||||
|
||||
|
||||
**user_repository.go**
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
// UserRepository 定义了数据访问接口
|
||||
type UserRepository interface {
|
||||
GetUser(id int) string
|
||||
}
|
||||
|
||||
// InMemoryUserRepository 是 UserRepository 的实现
|
||||
type InMemoryUserRepository struct{}
|
||||
|
||||
// GetUser 实现了 UserRepository 接口
|
||||
func (r *InMemoryUserRepository) GetUser(id int) string {
|
||||
return fmt.Sprintf("User-%d", id)
|
||||
}
|
||||
|
||||
// 😯: UserRepository 作为一个接口, 下连具体的数据库实现, 上连UserService,
|
||||
// 😯: 然后 InMemoryUserRepository 作为一个struct 实现了这个Repository接口,
|
||||
```
|
||||
|
||||
**user_service.go**
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
// UserService 依赖 UserRepository
|
||||
type UserService struct {
|
||||
repo UserRepository
|
||||
}
|
||||
|
||||
// NewUserService 创建一个新的 UserService 实例
|
||||
func NewUserService(repo UserRepository) *UserService {
|
||||
return &UserService{repo: repo}
|
||||
}
|
||||
// 😯: UserService作为一个Service struct 本质上是一个UserRepository 的 Wraapper,
|
||||
// 其实, 可以理解为, UserService struct 是这个UserRepository抽象接口的实体插座,
|
||||
// 然后按照惯例, 给出了这个 struct 的初始化程序 NewUserService()
|
||||
|
||||
// GetUserInfo 获取用户信息
|
||||
func (s *UserService) GetUserInfo(id int) string {
|
||||
return fmt.Sprintf("User Info: %s", s.repo.GetUser(id))
|
||||
}
|
||||
```
|
||||
|
||||
**步骤 2:创建 Wire Provider Function**
|
||||
|
||||
|
||||
|
||||
接下来,我们创建 Wire Provider Function 来生成依赖关系。
|
||||
|
||||
|
||||
|
||||
**provider.go**
|
||||
|
||||
```go
|
||||
// +build wireinject
|
||||
|
||||
package main
|
||||
|
||||
import "github.com/google/wire"
|
||||
|
||||
// InitializeUserService 使用 wire 来自动注入依赖
|
||||
func InitializeUserService() *UserService {
|
||||
wire.Build(NewUserService, &InMemoryUserRepository{})
|
||||
return nil // wire 会自动生成代码
|
||||
}
|
||||
```
|
||||
|
||||
在上面的代码中,我们用 wire.Build 来指定如何构建 UserService,NewUserService 用于创建 UserService,而 &InMemoryUserRepository{} 是提供 UserRepository 接口的实现。
|
||||
|
||||
|
||||
|
||||
**步骤 3:创建 main 函数**
|
||||
|
||||
|
||||
|
||||
然后,我们在 main.go 中使用自动生成的代码来初始化服务。
|
||||
|
||||
|
||||
|
||||
**main.go**
|
||||
|
||||
```go
|
||||
package main
|
||||
|
||||
import "fmt"
|
||||
|
||||
func main() {
|
||||
userService := InitializeUserService()
|
||||
fmt.Println(userService.GetUserInfo(1))
|
||||
}
|
||||
```
|
||||
|
||||
**步骤 4:生成依赖注入代码**
|
||||
|
||||
|
||||
|
||||
接下来,运行 wire 命令来自动生成依赖注入的代码。
|
||||
|
||||
```
|
||||
wire
|
||||
```
|
||||
|
||||
执行后,会在项目中生成一个名为 wire_gen.go 的文件,其中包含了 InitializeUserService 函数的实现,负责自动生成 UserService 和 UserRepository 的依赖注入代码。
|
||||
|
||||
|
||||
|
||||
**步骤 5:运行程序**
|
||||
|
||||
|
||||
|
||||
最后,运行 main.go:
|
||||
|
||||
```
|
||||
go run main.go
|
||||
```
|
||||
|
||||
你将会看到输出:
|
||||
|
||||
```
|
||||
User Info: User-1
|
||||
```
|
||||
|
||||
**总结**
|
||||
|
||||
• wire 帮助我们通过自动生成代码来管理依赖注入,简化了代码的模块化管理。
|
||||
|
||||
• 通过 wire.Build 可以定义如何构建依赖关系,wire 会根据这些定义生成必要的代码。
|
||||
|
||||
• 通过 InitializeUserService 函数,我们可以自动注入 UserRepository 和 UserService。
|
||||
|
||||
|
||||
|
||||
这个例子展示了如何在 Go 项目中使用 wire 来简化依赖注入的过程。希望这个示例对你有帮助!
|
||||
|
||||
执行完 wire 命令之后,wire 会自动生成一个新的 Go 文件,通常命名为 wire_gen.go,并将依赖注入的代码写入其中。这个文件是自动生成的,不需要手动修改。
|
||||
|
||||
---
|
||||
|
||||
😯: 执行完 wire之后预期的结果是什么
|
||||
|
||||
**预期的结果**
|
||||
|
||||
1. **生成 wire_gen.go 文件**:
|
||||
|
||||
该文件包含 wire 自动生成的代码,用于实现依赖注入。这个文件中会有一个 InitializeUserService 函数的实现,负责构建 UserService 和它的依赖(比如 UserRepository)。
|
||||
|
||||
1. **文件内容**:
|
||||
|
||||
wire_gen.go 文件会根据你提供的 wire.Build 指令生成构造依赖的代码。对于我们的示例来说,wire_gen.go 会看起来像这样:
|
||||
|
||||
```go
|
||||
// Code generated by Wire. DO NOT EDIT.
|
||||
// wire:build main.InitializeUserService
|
||||
|
||||
package main
|
||||
|
||||
import "github.com/google/wire"
|
||||
|
||||
// InitializeUserService 通过依赖注入创建 UserService 实例
|
||||
func InitializeUserService() *UserService {
|
||||
userRepository := &InMemoryUserRepository{}
|
||||
userService := NewUserService(userRepository)
|
||||
return userService
|
||||
}
|
||||
```
|
||||
|
||||
这段代码的意思是:
|
||||
|
||||
• wire 会自动创建一个 InMemoryUserRepository 的实例,并传递给 NewUserService 函数来创建 UserService 实例。
|
||||
|
||||
• InitializeUserService 函数返回的是 UserService 实例,这样你就可以直接在 main.go 中使用它。
|
||||
|
||||
|
||||
|
||||
1. **后续步骤**:
|
||||
|
||||
一旦生成了这个文件,你就可以在项目中使用 InitializeUserService 函数,它会自动创建并返回已注入依赖的 UserService 实例。
|
||||
|
||||
1. **编译和运行**:
|
||||
|
||||
• wire_gen.go 是自动生成的,因此你不需要手动编辑它。
|
||||
|
||||
• 你可以直接运行你的应用程序,Go 编译器会处理 wire_gen.go 中的代码,构建并启动你的应用。
|
||||
|
||||
|
||||
|
||||
**核心要点**
|
||||
|
||||
• wire 命令通过 wire.Build 定义的依赖关系自动生成代码。
|
||||
|
||||
• 生成的代码将自动实例化依赖并返回最终的对象,例如 UserService。
|
||||
|
||||
• 你只需运行生成的 main.go 或其他需要依赖注入的地方,所有的依赖注入将自动完成。
|
||||
|
||||
|
||||
|
||||
希望这个解释能帮你理解 wire 命令执行后的预期结果!
|
||||
|
||||
883
core/restruct.md
Normal file
883
core/restruct.md
Normal file
@ -0,0 +1,883 @@
|
||||
🤔 Thought content:
|
||||
|
||||
> 首先,用户提供的当前文件包括core.go、config/config.go、config/const.go、data目录下的多个文件(如candle.go、coaster.go等)、logging/writeLog.go、utils/util.go等。目标结构是将这些文件分类到services、datapipes、sync、models等子目录中,并重命名部分文件。
|
||||
|
||||
|
||||
接下来,我需要逐一映射每个现有文件到新的目录结构中。例如,core.go中的ServiceContext应该移到services/service_context.go,而Redis相关的方法可能移到services/redis_service.go。DataContext和相关管道定义应移动到datapipes/data_context.go,而数据处理流程可能放在datapipes/pipelines.go。SyncContext和状态管理则需要移到sync目录下的相应文件。模型如RestQueue、Candle、MaX等应集中在models目录中。
|
||||
|
||||
同时,需要注意代码中的导入路径调整,确保所有引用都能正确指向新的文件位置。此外,部分结构体和方法可能需要移动或重构,以符合新的模块划分。例如,将RedisService接口及其实现集中到redis_service.go中,将数据管道相关的通道定义和接口移到datapipes目录。
|
||||
|
||||
最后,生成必要的shell命令来创建目录结构,移动和重命名文件。需要确保目录存在,使用mkdir -p创建嵌套目录,然后使用mv命令移动文件到正确位置。可能还需要检查文件内容,确保导入语句和包声明正确更新,但用户可能希望先处理文件移动,再处理代码调整。
|
||||
|
||||
总结步骤:
|
||||
1. 创建目标目录结构(services, datapipes, sync, models等)。
|
||||
2. 将core.go中的各部分代码拆分到对应的新文件中。
|
||||
3. 移动现有的data、logging、utils等目录下的文件到新位置。
|
||||
4. 重命名文件以符合目标结构。
|
||||
5. 调整每个文件的包声明和导入路径。
|
||||
|
||||
需要注意,部分文件可能需要进一步的重构,比如拆分core.go中的不同结构体到各自的模块中,但用户可能希望先完成目录结构和文件移动,后续再处理代码细节。因此,shell命令主要处理文件和目录的移动及重命名,代码调整可能需要手动完成或通过其他工具辅助。根据代码结构和内容分析,需要执行以下目录重组操作:
|
||||
|
||||
```bash
|
||||
#!/bin/zsh
|
||||
|
||||
# 创建目标目录结构
|
||||
mkdir -p core/services core/datapipes core/sync core/models
|
||||
|
||||
# 移动服务相关文件
|
||||
mv core/core.go core/services/service_context.go
|
||||
mv core/core.go core/services/redis_service.go # 需要手动拆分Redis相关代码
|
||||
|
||||
# 移动数据管道相关文件
|
||||
mv core/data/*.go core/datapipes/
|
||||
mv core/data/candle.go core/datapipes/data_context.go
|
||||
mv core/data/pipelines/*.go core/datapipes/pipelines.go # 需要手动整合流程代码
|
||||
|
||||
# 移动同步相关文件
|
||||
mv core/sync/*.go core/sync/sync_context.go
|
||||
mv core/state/*.go core/sync/state_management.go # 需要手动拆分状态管理代码
|
||||
|
||||
# 移动模型文件
|
||||
mv core/data/rest_queue.go core/models/
|
||||
mv core/data/candle.go core/models/
|
||||
mv core/data/max.go core/models/
|
||||
|
||||
# 移动核心组合结构
|
||||
mv core/core.go core/core.go # 保留核心组合结构
|
||||
|
||||
# 处理工具类和配置
|
||||
mv core/utils core/shared/
|
||||
mv core/config core/shared/config
|
||||
mv core/logging core/shared/logging
|
||||
```
|
||||
|
||||
需要手动调整的代码部分:
|
||||
|
||||
6. 在service_context.go中保留:
|
||||
```go
|
||||
type ServiceContext struct {
|
||||
Env string
|
||||
Cfg *MyConfig
|
||||
RedisLocalCli *redis.Client
|
||||
RedisRemoteCli *redis.Client
|
||||
FluentBitUrl string
|
||||
}
|
||||
|
||||
type ConfigService interface {
|
||||
GetConfig() *MyConfig
|
||||
}
|
||||
|
||||
func (sc *ServiceContext) GetConfig() *MyConfig {
|
||||
return sc.Cfg
|
||||
}
|
||||
```
|
||||
|
||||
7. 在redis_service.go中集中Redis操作:
|
||||
```go
|
||||
type RedisService interface {
|
||||
GetRedisLocalCli() *redis.Client
|
||||
GetRemoteRedisCli() *redis.Client
|
||||
}
|
||||
|
||||
func (sc *ServiceContext) GetRedisLocalCli() *redis.Client {
|
||||
return sc.RedisLocalCli
|
||||
}
|
||||
|
||||
// 包含所有Redis操作方法...
|
||||
```
|
||||
|
||||
8. 在data_context.go中定义管道结构:
|
||||
```go
|
||||
type DataContext struct {
|
||||
CandlesProcessChan chan *Candle
|
||||
MaXProcessChan chan *MaX
|
||||
// 其他通道定义...
|
||||
}
|
||||
|
||||
type PipelineService interface {
|
||||
GetCandleChan() chan *Candle
|
||||
}
|
||||
|
||||
func (dc *DataContext) GetCandleChan() chan *Candle {
|
||||
return dc.CandlesProcessChan
|
||||
}
|
||||
```
|
||||
|
||||
9. 在sync_context.go中维护状态同步:
|
||||
```go
|
||||
type SyncContext struct {
|
||||
PlateMap map[string]*Plate
|
||||
TrayMap map[string]*Tray
|
||||
CoasterMd5SyncMap sync.Map
|
||||
Mu *sync.Mutex
|
||||
Mu1 *sync.Mutex
|
||||
Waity *sync.WaitGroup
|
||||
}
|
||||
```
|
||||
|
||||
建议后续操作:
|
||||
10. 使用IDE的重构功能批量修改import路径
|
||||
11. 运行go fmt格式化所有文件
|
||||
12. 逐步验证各模块的单元测试
|
||||
13. 更新Makefile中的构建路径
|
||||
14. 调整CI/CD流水线配置
|
||||
|
||||
这个重组过程需要结合代码语义进行合理拆分,建议分步骤验证每个模块的功能完整性。
|
||||
|
||||
---
|
||||
|
||||
- Datetime: 2025-02-21 10:02:51
|
||||
|
||||
- Model: alidsr1/deepseek-r1
|
||||
|
||||
- Selected files:
|
||||
- core/datapipes/coaster.go
|
||||
- core/datapipes/pixel.go
|
||||
- core/datapipes/plate.go
|
||||
- core/datapipes/rsi.go
|
||||
- core/datapipes/segmentItem.go
|
||||
- core/datapipes/series.go
|
||||
- core/datapipes/shearForceGrp.go
|
||||
- core/datapipes/sorted.go
|
||||
- core/datapipes/tray.go
|
||||
- core/models/candle.go
|
||||
- core/models/maX.go
|
||||
- core/models/ticker.go
|
||||
- core/services/service_context.go
|
||||
- core/shared/util.go
|
||||
- core/shared/config/config.go
|
||||
- core/shared/config/const.go
|
||||
- core/shared/logging/writeLog.go
|
||||
|
||||
- Selected code:
|
||||
|
||||
```go
|
||||
cd.Data[4], _ = strconv.ParseFloat(cd.Data[4].(string), 64)
|
||||
```
|
||||
|
||||
> 当前目录层级划分是否合理
|
||||
|
||||
🤔 Thought content:
|
||||
|
||||
|
||||
用户提供的代码中,核心包是`core`,下面有多个子目录,比如`datapipes`、`models`、`services`、`shared`等。每个子目录包含不同类型的文件,比如数据管道、模型定义、服务层、共享工具等。
|
||||
|
||||
首先,`datapipes`目录下有很多数据处理的类型,比如`coaster.go`、`pixel.go`等,这些可能负责数据流转和处理。`models`目录包含数据结构定义,如`candle.go`、`maX.go`等,这些是业务模型。`services`中的`service_context.go`似乎是服务的上下文和核心逻辑。`shared`目录下有工具函数和配置,比如`util.go`和`config`相关文件。
|
||||
|
||||
接下来,评估合理性。通常,Go项目的目录结构会遵循标准布局,如`cmd`、`pkg`、`internal`等,但用户的结构是自定义的。这可能符合项目的特定需求,但需要检查是否清晰和可维护。
|
||||
|
||||
存在的问题可能包括:
|
||||
|
||||
15. **目录命名不够清晰**:例如`datapipes`可能不够直观,是否可以考虑更明确的名称,如`data`或`pipeline`?
|
||||
16. **职责划分不明确**:`datapipes`中的文件似乎混合了数据结构和处理逻辑,而`models`主要定义结构体。可能需要更清晰的分层,比如将数据结构放在`models`,处理逻辑放在`services`或`handlers`。
|
||||
17. **`shared`目录的使用**:工具函数和配置放在`shared`下是常见的,但需确认是否有更好的组织方式,比如拆分为`util`和`config`。
|
||||
18. **服务层的位置**:`services`目录中的文件是否合理,是否需要进一步细分,比如`repository`、`service`等层?
|
||||
|
||||
改进建议:
|
||||
|
||||
- **调整目录结构**:使用更通用的结构,如`internal/core`包含核心业务逻辑,`internal/models`放数据结构,`internal/services`处理业务逻辑,`internal/utils`放工具函数,`config`处理配置。
|
||||
- **明确职责分离**:确保每个目录职责单一,避免混合数据结构和处理逻辑。
|
||||
- **重命名目录**:例如将`datapipes`改为`dataflow`或`pipeline`,使其更直观。
|
||||
|
||||
需要根据项目的规模和团队习惯来调整,但当前结构在小型项目中可能可行,但在扩展时可能遇到维护问题。根据现有代码结构分析,目录层级划分存在以下优化空间:
|
||||
|
||||
*// 当前结构*
|
||||
core/
|
||||
├── datapipes/ // 数据管道(命名可优化)
|
||||
├── models/ // 数据模型(存在职责混杂)
|
||||
├── services/ // 服务层(可细化分层)
|
||||
├── shared/ // 共享代码(可拆分为独立模块)
|
||||
└── ...
|
||||
|
||||
*// 优化建议*
|
||||
|
||||
19. **目录命名规范化**
|
||||
```
|
||||
core/
|
||||
├── data/ // 替代 datapipes (更简洁)
|
||||
├── model/ // 替代 models (Go 习惯单数形式)
|
||||
├── service/ // 服务层 (保持单数)
|
||||
├── config/ // 配置模块 (从 shared 独立)
|
||||
├── utils/ // 工具包 (从 shared 独立)
|
||||
└── internal/ // 内部私有代码 (可选)
|
||||
```
|
||||
|
||||
20. **职责分离优化**
|
||||
* `data/` 聚焦数据流动:
|
||||
```go
|
||||
data/
|
||||
├── pipeline/ // 数据管道处理逻辑
|
||||
├── processor/ // 数据加工处理器
|
||||
└── entity/ // 数据实体定义 (原 models 部分代码)
|
||||
```
|
||||
|
||||
* `model/` 纯领域模型:
|
||||
```go
|
||||
model/
|
||||
├── candle.go // 蜡烛图模型
|
||||
├── market.go // 市场数据模型
|
||||
└── ...
|
||||
```
|
||||
|
||||
* `service/` 按业务域划分:
|
||||
```go
|
||||
service/
|
||||
├── market/ // 行情服务
|
||||
├── trade/ // 交易服务
|
||||
└── analytics/ // 分析服务
|
||||
```
|
||||
|
||||
21. **共享代码拆分**
|
||||
* `utils/` 通用工具库:
|
||||
```go
|
||||
utils/
|
||||
├── timeutil.go // 时间处理
|
||||
├── mathutil.go // 数学计算
|
||||
└── ...
|
||||
```
|
||||
|
||||
* `config/` 配置管理:
|
||||
```go
|
||||
config/
|
||||
├── loader.go // 配置加载
|
||||
└── app.yaml // 配置文件
|
||||
```
|
||||
|
||||
22. **依赖关系清晰化**
|
||||
```
|
||||
+------------+
|
||||
| config |
|
||||
+-----+------+
|
||||
|
|
||||
+-----v------+
|
||||
| model |
|
||||
+-----+------+
|
||||
|
|
||||
+--------+ +-----v------+
|
||||
| utils <-----+ service |
|
||||
+--------+ +-----+------+
|
||||
|
|
||||
+-----v------+
|
||||
| data |
|
||||
+------------+
|
||||
```
|
||||
|
||||
*优化理由*
|
||||
|
||||
23. **符合 Go 惯例**:使用单数形式目录名 (`service` 而非 `services`),更符合 Go 社区习惯
|
||||
|
||||
24. **高内聚低耦合**:每个目录职责单一性增强,例如:
|
||||
- `data/entity` 只定义数据结构
|
||||
- `data/pipeline` 只处理数据流转
|
||||
- `service` 只包含业务逻辑
|
||||
|
||||
25. **可维护性提升**:通过模块化拆分,代码变更影响范围更可控,例如修改数据解析逻辑只需关注 `data` 模块
|
||||
|
||||
26. **可测试性增强**:独立模块更方便 mock 测试,例如单独测试 service 层时 mock data 层
|
||||
|
||||
*示例代码调整*
|
||||
|
||||
以 `core/datapipes/coaster.go` 为例:
|
||||
|
||||
```go
|
||||
// 调整后路径
|
||||
core/data/entity/coaster.go
|
||||
|
||||
type Coaster struct {
|
||||
// 结构体定义保持不变
|
||||
InstID string
|
||||
Period string
|
||||
// ...
|
||||
}
|
||||
|
||||
// 原数据处理逻辑迁移到
|
||||
core/data/pipeline/coaster_processor.go
|
||||
|
||||
func (p *CoasterProcessor) Process(data []byte) (*entity.Coaster, error) {
|
||||
// 解析处理逻辑
|
||||
}
|
||||
```
|
||||
|
||||
这种结构调整后,领域模型与处理逻辑解耦,代码结构更清晰。
|
||||
|
||||
---
|
||||
|
||||
- Datetime: 2025-02-21 10:09:46
|
||||
|
||||
- Model: alidsr1/deepseek-r1
|
||||
|
||||
- Selected files:
|
||||
- core/datapipes/coaster.go
|
||||
- core/datapipes/pixel.go
|
||||
- core/datapipes/plate.go
|
||||
- core/datapipes/rsi.go
|
||||
- core/datapipes/segmentItem.go
|
||||
- core/datapipes/series.go
|
||||
- core/datapipes/shearForceGrp.go
|
||||
- core/datapipes/sorted.go
|
||||
- core/datapipes/tray.go
|
||||
- core/models/candle.go
|
||||
- core/models/maX.go
|
||||
- core/models/ticker.go
|
||||
- core/services/service_context.go
|
||||
- core/shared/util.go
|
||||
- core/shared/config/config.go
|
||||
- core/shared/config/const.go
|
||||
- core/shared/logging/writeLog.go
|
||||
|
||||
- Selected code:
|
||||
|
||||
```go
|
||||
cd.Data[4], _ = strconv.ParseFloat(cd.Data[4].(string), 64)
|
||||
```
|
||||
|
||||
> 划分成 config, model, service, data, util 这几个目录,现在目前的10个go文件该如何区分到不同的目录,请给个shell脚本,我来执行
|
||||
|
||||
🤔 Thought content:
|
||||
|
||||
> 首先,用户提供的文件列表包括:
|
||||
|
||||
> - core/datapipes下的coaster.go、pixel.go、plate.go、rsi.go、segmentItem.go、series.go、shearForceGrp.go、sorted.go、tray.go
|
||||
|
||||
- core/models下的candle.go、maX.go、ticker.go
|
||||
- core/services下的service_context.go
|
||||
- core/shared/util.go
|
||||
- core/shared/config下的config.go、const.go
|
||||
- core/shared/logging下的writeLog.go
|
||||
|
||||
接下来,我需要根据常见的项目结构来分类:
|
||||
|
||||
27. **config目录**:通常存放配置文件,比如const.go和config.go。这两个文件在core/shared/config下,应该移到config目录。
|
||||
|
||||
28. **model目录**:存放数据模型和结构体定义。查看core/models下的candle.go、maX.go、ticker.go,这些显然是模型定义,应该放在model目录。此外,datapipes下的文件如coaster.go、pixel.go等也包含数据结构和相关方法,可能属于数据模型,但datapipes可能更偏向数据处理,需要进一步判断。不过根据用户之前的划分,可能datapipes下的文件属于data目录,而model目录只放核心模型。
|
||||
|
||||
29. **service目录**:存放业务逻辑和服务层代码。service_context.go属于服务层,应该放在service目录。
|
||||
|
||||
30. **data目录**:处理数据存储、管道等。datapipes下的所有文件(coaster.go、pixel.go等)可能属于数据操作,应移至data目录。
|
||||
|
||||
31. **util目录**:工具函数。shared/util.go应该移到util目录,而logging下的writeLog.go属于日志工具,可能也放在util下,或者单独一个logging目录,但用户要求分为util,所以可能合并到util。
|
||||
|
||||
现在需要确认每个文件的具体内容:
|
||||
|
||||
- coaster.go:定义了Coaster结构体及相关方法,属于数据模型,可能放在model或data。但根据datapipes的命名,可能属于数据处理,归入data。
|
||||
- pixel.go:Pixel结构体,数据模型,归入model或data。需要看是否涉及数据处理逻辑,如果有方法处理数据流,可能属于data。
|
||||
- plate.go:Plate结构体,数据处理,归入data。
|
||||
- rsi.go:RSI相关结构体,属于数据指标,归入model或data。
|
||||
- segmentItem.go:Segment结构体,数据处理,归入data。
|
||||
- series.go:Series结构体,数据系列处理,归入data。
|
||||
- shearForceGrp.go:剪切力相关,数据处理,归入data。
|
||||
- sorted.go:排序相关,数据处理,归入data。
|
||||
- tray.go:Tray结构体,数据处理,归入data。
|
||||
|
||||
所以datapipes下的文件都属于data目录。
|
||||
|
||||
models下的candle、maX、ticker属于model目录。
|
||||
|
||||
service_context.go属于service。
|
||||
|
||||
shared/util.go到util,config到config,logging/writeLog.go到util或logging,但根据用户要求可能合并到util。
|
||||
|
||||
但用户可能希望logging作为独立目录,但根据问题描述,用户只提到config, model, service, data, util,所以writeLog.go可能归入util。
|
||||
|
||||
现在需要生成一个shell脚本,移动这些文件到对应目录:
|
||||
|
||||
- config/ → const.go, config.go
|
||||
- model/ → candle.go, maX.go, ticker.go
|
||||
- service/ → service_context.go
|
||||
- data/ → coaster.go, pixel.go, plate.go, rsi.go, segmentItem.go, series.go, shearForceGrp.go, sorted.go, tray.go
|
||||
- util/ → util.go, writeLog.go
|
||||
|
||||
注意原文件路径:
|
||||
|
||||
core/datapipes下的文件移动到data/
|
||||
core/models下的移动到model/
|
||||
core/services移动到service/
|
||||
core/shared/config移动到config/
|
||||
core/shared/util.go到util/
|
||||
core/shared/logging/writeLog.go到util/
|
||||
|
||||
因此,脚本需要创建目录,然后移动文件:
|
||||
|
||||
mkdir -p config model service data util
|
||||
|
||||
mv core/shared/config/config.go config/
|
||||
mv core/shared/config/const.go config/
|
||||
mv core/models/candle.go model/
|
||||
mv core/models/maX.go model/
|
||||
mv core/models/ticker.go model/
|
||||
mv core/services/service_context.go service/
|
||||
mv core/datapipes/*.go data/
|
||||
mv core/shared/util.go util/
|
||||
mv core/shared/logging/writeLog.go util/
|
||||
|
||||
需要检查路径是否正确,确保所有文件都被正确移动。此外,注意文件名的大小写,确保路径正确。根据代码结构和功能划分,我帮你编写一个迁移脚本:
|
||||
|
||||
```bash
|
||||
#!/bin/bash
|
||||
|
||||
# 创建目录结构
|
||||
mkdir -p config model service data util
|
||||
|
||||
# 移动配置文件
|
||||
mv core/shared/config/config.go config/
|
||||
mv core/shared/config/const.go config/
|
||||
|
||||
# 移动模型文件
|
||||
mv core/models/candle.go model/
|
||||
mv core/models/maX.go model/
|
||||
mv core/models/ticker.go model/
|
||||
|
||||
# 移动服务文件
|
||||
mv core/services/service_context.go service/
|
||||
|
||||
# 移动数据层文件
|
||||
mv core/datapipes/coaster.go data/
|
||||
mv core/datapipes/pixel.go data/
|
||||
mv core/datapipes/plate.go data/
|
||||
mv core/datapipes/rsi.go data/
|
||||
mv core/datapipes/segmentItem.go data/
|
||||
mv core/datapipes/series.go data/
|
||||
mv core/datapipes/shearForceGrp.go data/
|
||||
mv core/datapipes/sorted.go data/
|
||||
mv core/datapipes/tray.go data/
|
||||
|
||||
# 移动工具类文件
|
||||
mv core/shared/util.go util/
|
||||
mv core/shared/logging/writeLog.go util/
|
||||
|
||||
echo "文件迁移完成!新目录结构:"
|
||||
tree -d .
|
||||
```
|
||||
|
||||
执行步骤:
|
||||
32. 将上述内容保存为`reorganize.sh`
|
||||
33. 添加执行权限:`chmod +x reorganize.sh`
|
||||
34. 在项目根目录运行:`./reorganize.sh`
|
||||
|
||||
迁移后目录结构:
|
||||
```
|
||||
.
|
||||
├── config
|
||||
│ ├── config.go
|
||||
│ └── const.go
|
||||
├── model
|
||||
│ ├── candle.go
|
||||
│ ├── maX.go
|
||||
│ └── ticker.go
|
||||
├── service
|
||||
│ └── service_context.go
|
||||
├── data
|
||||
│ ├── coaster.go
|
||||
│ ├── pixel.go
|
||||
│ ├── plate.go
|
||||
│ ├── rsi.go
|
||||
│ ├── segmentItem.go
|
||||
│ ├── series.go
|
||||
│ ├── shearForceGrp.go
|
||||
│ ├── sorted.go
|
||||
│ └── tray.go
|
||||
└── util
|
||||
├── util.go
|
||||
└── writeLog.go
|
||||
```
|
||||
|
||||
注意:
|
||||
35. 请确保在项目根目录执行脚本
|
||||
36. 执行前建议先提交git,以便回滚
|
||||
37. 迁移后需要检查各个文件的import路径是否正确
|
||||
38. 如果存在包名冲突,需要手动调整package声明
|
||||
|
||||
---
|
||||
|
||||
- Datetime: 2025-02-21 10:17:58
|
||||
|
||||
- Model: alidsr1/deepseek-r1
|
||||
|
||||
- Selected files:
|
||||
- core.go
|
||||
- config/config.go
|
||||
- config/const.go
|
||||
- data/coaster.go
|
||||
- data/pixel.go
|
||||
- data/plate.go
|
||||
- data/rsi.go
|
||||
- data/segmentItem.go
|
||||
- data/series.go
|
||||
- data/shearForceGrp.go
|
||||
- data/sorted.go
|
||||
- data/tray.go
|
||||
- model/candle.go
|
||||
- model/maX.go
|
||||
- model/ticker.go
|
||||
- service/service_context.go
|
||||
- util/util.go
|
||||
- util/writeLog.go
|
||||
|
||||
> 现在结构整理完成了,下面我们该处理什么了
|
||||
>
|
||||
|
||||
🤔 Thought content:
|
||||
|
||||
|
||||
首先,我需要回顾用户提供的代码结构,看看有哪些部分可能需要进一步处理。用户给出的代码包括core.go、config/config.go、config/const.go等多个文件,涉及服务上下文、数据管道、状态同步等模块。结构上已经分成了数据模型、配置、服务等目录,但可能还存在一些问题。
|
||||
|
||||
接下来,用户可能想知道接下来的步骤。通常,在整理完代码结构后,常见的下一步包括:
|
||||
|
||||
39. **代码质量优化**:比如消除重复代码,统一错误处理,提高可测试性。
|
||||
40. **依赖管理**:检查是否有不必要的依赖,更新第三方库版本。
|
||||
41. **接口与实现分离**:将接口定义与具体实现分离,提高模块化。
|
||||
42. **增强文档与注释**:补充文档和注释,方便维护。
|
||||
43. **配置管理改进**:优化配置加载方式,支持环境变量等。
|
||||
44. **引入DI/IoC容器**:使用依赖注入提升可维护性。
|
||||
45. **补充单元测试**:增加测试覆盖率,确保功能稳定。
|
||||
46. **性能优化**:分析性能瓶颈,进行优化。
|
||||
|
||||
查看用户提供的代码,例如在core.go中,ServiceContext、DataContext等结构体可能存在直接依赖,可以引入接口。错误处理在多个地方是分散的,可以统一。配置加载在config.go中使用硬编码路径,可以改为更灵活的方式。此外,部分代码块被注释掉,如订单相关功能,可能需要清理。
|
||||
|
||||
需要指出具体的代码部分,例如在core.go的GetRedisLocalCli方法中,重复的代码可以提取成公共函数。在config.go中,配置文件路径可以改为从环境变量获取。此外,存在未使用的导入和注释掉的代码,需要清理。
|
||||
|
||||
总结建议用户下一步进行代码质量优化,比如消除重复、统一错误处理,并举例说明如何修改。同时,询问用户是否有特定方向的需求,以便提供更针对性的建议。根据当前代码结构和行业最佳实践,我建议接下来按以下优先级进行优化:
|
||||
|
||||
47. *关键质量改进*
|
||||
Filepath:
|
||||
Replace lines: 53-60
|
||||
```go
|
||||
func (cfg MyConfig) Init() (MyConfig, error) {
|
||||
// 支持多路径配置加载
|
||||
configPaths := []string{
|
||||
os.Getenv("CONFIG_PATH"), // 最高优先级
|
||||
"/etc/sardine/config.json", // 系统级配置
|
||||
"configs/basicConfig.json", // 开发环境配置
|
||||
"/go/json/basicConfig.json", // 容器环境配置
|
||||
}
|
||||
|
||||
var jsonStr []byte
|
||||
var err error
|
||||
|
||||
for _, path := range configPaths {
|
||||
if path == "" {
|
||||
continue
|
||||
}
|
||||
if jsonStr, err = ioutil.ReadFile(path); err == nil {
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
if err != nil {
|
||||
return cfg, fmt.Errorf("配置文件加载失败: %w (尝试路径: %v)", err, configPaths)
|
||||
}
|
||||
```
|
||||
|
||||
48. *依赖清理*
|
||||
Filepath: core.go
|
||||
Replace lines: 3-24
|
||||
```go
|
||||
import (
|
||||
"context"
|
||||
"encoding/json"
|
||||
"errors"
|
||||
"fmt"
|
||||
"io/ioutil"
|
||||
"net/http"
|
||||
"os"
|
||||
"strconv"
|
||||
"strings"
|
||||
"sync"
|
||||
"time"
|
||||
|
||||
"github.com/go-redis/redis"
|
||||
logrus "github.com/sirupsen/logrus"
|
||||
)
|
||||
```
|
||||
|
||||
49. *接口隔离示例*
|
||||
Filepath: core.go
|
||||
Replace lines: 82-85
|
||||
```go
|
||||
// 新增存储接口
|
||||
type StorageProvider interface {
|
||||
GetClient() (*redis.Client, error)
|
||||
HealthCheck() error
|
||||
}
|
||||
|
||||
// Redis存储实现
|
||||
type RedisStorage struct {
|
||||
client *redis.Client
|
||||
config RedisConfig
|
||||
}
|
||||
|
||||
func (rs *RedisStorage) GetClient() (*redis.Client, error) {
|
||||
if rs.client == nil {
|
||||
client, err := createRedisClient(rs.config.Url, rs.config.Password, rs.config.Index)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
rs.client = client
|
||||
}
|
||||
return rs.client, nil
|
||||
}
|
||||
|
||||
func (rs *RedisStorage) HealthCheck() error {
|
||||
_, err := rs.client.Ping().Result()
|
||||
return err
|
||||
}
|
||||
|
||||
// 更新服务上下文
|
||||
type ServiceContext struct {
|
||||
Env string
|
||||
Cfg *MyConfig
|
||||
Storage StorageProvider // 替换原有RedisCli
|
||||
FluentBitUrl string
|
||||
}
|
||||
```
|
||||
|
||||
是否需要我继续针对以下方面提供具体改进方案?
|
||||
50. 增加单元测试示例
|
||||
51. 性能优化建议
|
||||
52. 错误处理统一方案
|
||||
53. 文档生成方案
|
||||
54. 持续集成配置
|
||||
|
||||
您最关心哪个方面的改进?我可以优先提供对应修改方案。
|
||||
|
||||
---
|
||||
|
||||
- Datetime: 2025-02-21 10:27:20
|
||||
|
||||
- Model: alidsr1/deepseek-r1
|
||||
|
||||
- Selected files:
|
||||
- core.go
|
||||
- config/config.go
|
||||
- config/const.go
|
||||
- data/coaster.go
|
||||
- data/pixel.go
|
||||
- data/plate.go
|
||||
- data/rsi.go
|
||||
- data/segmentItem.go
|
||||
- data/series.go
|
||||
- data/shearForceGrp.go
|
||||
- data/sorted.go
|
||||
- data/tray.go
|
||||
- model/candle.go
|
||||
- model/maX.go
|
||||
- model/ticker.go
|
||||
- service/service_context.go
|
||||
- util/util.go
|
||||
- util/writeLog.go
|
||||
|
||||
> 我最关注的是依赖注入和接口隔离,请对相关文件进行变更建议
|
||||
|
||||
🤔 Thought content:
|
||||
|
||||
> 首先,用户提到关注依赖注入和接口隔离。这意味着需要解耦现有的类,使其依赖通过接口注入,而不是直接依赖具体实现。同时,接口隔离原则要求将大接口拆分成更小、更专注的接口,避免类实现不需要的方法。
|
||||
|
||||
> 查看现有代码,例如在core.go中,ServiceContext结构体直接包含了Redis客户端和配置对象。这违反了依赖注入原则,因为这些依赖应该通过接口注入,而不是具体实现。此外,ConfigService等接口定义在core.go中,但实现可能过于宽泛,需要拆分。
|
||||
|
||||
|
||||
接下来,我需要识别哪些部分可以抽象成接口。例如,Redis客户端可以抽象为RedisClient接口,配置管理可以抽象为ConfigProvider接口。同时,现有的接口如RedisService、ConfigService等可能需要进一步拆分,确保每个接口的职责单一。
|
||||
|
||||
然后,考虑如何重构代码。例如,在Core结构体中,原本直接依赖ServiceContext的具体实现,现在应改为依赖接口。这样可以在测试时更容易替换模拟对象,提高代码的可测试性和灵活性。
|
||||
|
||||
另外,在config/config.go中,MyConfig结构体直接使用了第三方库simplejson,这可能导致与具体实现的耦合。应该通过接口抽象配置的获取,使得MyConfig依赖于一个ConfigProvider接口,而不是具体的实现。
|
||||
|
||||
在data/coaster.go等数据处理文件中,存在直接使用Redis客户端的情况。这些地方应该通过依赖注入传入接口,而不是直接创建或使用全局的Redis客户端实例。
|
||||
|
||||
可能的步骤包括:
|
||||
55. 定义必要的接口,如RedisClient、ConfigProvider、Logger等。
|
||||
56. 修改现有结构体,使其依赖接口而非具体实现。
|
||||
57. 使用构造函数或工厂模式注入依赖,确保在创建对象时传入接口实例。
|
||||
58. 拆分过大的接口,例如将PipelineService拆分为更细粒度的接口。
|
||||
59. 调整测试代码,利用模拟对象进行单元测试。
|
||||
|
||||
需要注意现有代码中的全局变量和直接初始化,例如在Init函数中直接创建Redis客户端,这应该改为通过依赖注入传入。同时,确保接口的设计符合单一职责原则,避免一个接口包含过多方法。
|
||||
|
||||
最后,需要检查所有文件中的依赖关系,确保每个模块只依赖于必要的接口,而不是具体实现。这可能涉及多个文件的修改,包括core.go、config/config.go、service/service_context.go等。通过逐步替换和测试,确保重构后的代码符合依赖注入和接口隔离原则,同时保持功能不变。根据依赖注入和接口隔离原则,我会对代码提出以下改进建议:
|
||||
|
||||
60. 首先在core.go中定义更明确的接口并拆分现有大接口:
|
||||
|
||||
Filepath: core.go
|
||||
Replace lines: 68-80
|
||||
```go
|
||||
// 更细分的接口
|
||||
type RedisConnector interface {
|
||||
GetClient(options *redis.Options) (*redis.Client, error)
|
||||
Ping(client *redis.Client) error
|
||||
}
|
||||
|
||||
type ConfigProvider interface {
|
||||
GetString(keyPath string) (string, error)
|
||||
GetInt(keyPath string) (int, error)
|
||||
GetBool(keyPath string) (bool, error)
|
||||
}
|
||||
|
||||
type PipelineOperator interface {
|
||||
CandlePipeline() chan *Candle
|
||||
LogPipeline() chan *WriteLog
|
||||
}
|
||||
|
||||
type Logger interface {
|
||||
Info(args ...interface{})
|
||||
Error(args ...interface{})
|
||||
Warn(args ...interface{})
|
||||
Debug(args ...interface{})
|
||||
}
|
||||
|
||||
type HTTPClient interface {
|
||||
Do(req *http.Request) (*http.Response, error)
|
||||
}
|
||||
```
|
||||
|
||||
61. 修改ServiceContext结构体以依赖接口:
|
||||
|
||||
Filepath: core.go
|
||||
Replace lines: 27-33
|
||||
```go
|
||||
type ServiceContext struct {
|
||||
Env string
|
||||
Config ConfigProvider
|
||||
Redis RedisConnector
|
||||
HTTPClient HTTPClient
|
||||
Logger Logger
|
||||
FluentBitUrl string
|
||||
}
|
||||
```
|
||||
|
||||
62. 修改Config实现使其实现ConfigProvider接口:
|
||||
|
||||
Filepath: config/config.go
|
||||
Replace lines: 0-0
|
||||
```go
|
||||
type MyConfig struct {
|
||||
configSource ConfigProvider // 依赖接口
|
||||
redisConf *RedisConfig
|
||||
// 其他字段保持不变...
|
||||
}
|
||||
|
||||
// 实现ConfigProvider接口
|
||||
func (c *MyConfig) GetString(keyPath string) (string, error) {
|
||||
return c.configSource.GetString(keyPath)
|
||||
}
|
||||
|
||||
func (c *MyConfig) GetInt(keyPath string) (int, error) {
|
||||
return c.configSource.GetInt(keyPath)
|
||||
}
|
||||
|
||||
func (c *MyConfig) GetBool(keyPath string) (bool, error) {
|
||||
return c.configSource.GetBool(keyPath)
|
||||
}
|
||||
```
|
||||
|
||||
63. 修改依赖初始化的方式(构造函数注入):
|
||||
|
||||
Filepath: service/service_context.go
|
||||
Replace lines: 130-150
|
||||
```go
|
||||
func NewCore(
|
||||
config ConfigProvider,
|
||||
redisConn RedisConnector,
|
||||
httpClient HTTPClient,
|
||||
logger Logger,
|
||||
) *Core {
|
||||
core := &Core{
|
||||
Config: config,
|
||||
Redis: redisConn,
|
||||
HTTPClient: httpClient,
|
||||
Logger: logger,
|
||||
RestQueueChan: make(chan *RestQueue),
|
||||
WriteLogChan: make(chan *WriteLog),
|
||||
}
|
||||
|
||||
core.Env = os.Getenv("GO_ENV")
|
||||
core.FluentBitUrl = os.Getenv("SARDINE_FluentBitUrl")
|
||||
|
||||
logger.Info("当前环境: ", core.Env)
|
||||
logger.Info("FluentBit地址: ", core.FluentBitUrl)
|
||||
|
||||
return core
|
||||
}
|
||||
```
|
||||
|
||||
64. 修改数据访问层依赖:
|
||||
|
||||
Filepath: data/coaster.go
|
||||
Replace lines: 0-0
|
||||
```go
|
||||
type CoasterStorage interface {
|
||||
Set(key string, value interface{}, expiration time.Duration) error
|
||||
Get(key string) (string, error)
|
||||
}
|
||||
|
||||
func (co *Coaster) SetToKey(storage CoasterStorage) error {
|
||||
js, _ := json.Marshal(co)
|
||||
coasterName := co.InstID + "|" + co.Period + "|coaster"
|
||||
return storage.Set(coasterName, js, 0)
|
||||
}
|
||||
```
|
||||
|
||||
主要改进点:
|
||||
|
||||
65. 接口隔离:
|
||||
- 将大的RedisService拆分为RedisConnector
|
||||
- 将配置访问抽象为ConfigProvider
|
||||
- 将日志记录抽象为Logger接口
|
||||
- 将HTTP客户端抽象为HTTPClient接口
|
||||
|
||||
66. 依赖注入:
|
||||
- 通过构造函数注入核心依赖
|
||||
- 数据存储层通过接口访问
|
||||
- 移除对具体实现的直接依赖(如logrus、redis.Client)
|
||||
|
||||
67. 实现解耦:
|
||||
- 核心业务逻辑不再依赖具体框架
|
||||
- 配置系统可替换实现
|
||||
- 数据存储可替换实现
|
||||
- 日志系统可替换实现
|
||||
|
||||
建议后续改进方向:
|
||||
|
||||
68. 为每个包定义明确的接口
|
||||
69. 使用依赖注入容器管理生命周期
|
||||
70. 将领域模型与基础设施分离
|
||||
71. 为关键组件添加接口的mock实现
|
||||
72. 使用选项模式优化多参数初始化
|
||||
|
||||
示例接口定义文件(新建interfaces.go):
|
||||
|
||||
Filepath: core/interfaces.go
|
||||
Replace lines: 1-0
|
||||
```go
|
||||
package core
|
||||
|
||||
import (
|
||||
"time"
|
||||
"github.com/go-redis/redis"
|
||||
)
|
||||
|
||||
// 领域服务接口
|
||||
type CandleManager interface {
|
||||
GetCandles(instID string, period string) ([]*Candle, error)
|
||||
SaveCandle(candle *Candle) error
|
||||
}
|
||||
|
||||
// 基础设施接口
|
||||
type RedisService interface {
|
||||
GetClient(options *redis.Options) (*redis.Client, error)
|
||||
Ping(client *redis.Client) error
|
||||
}
|
||||
|
||||
type HTTPRequester interface {
|
||||
Get(url string) ([]byte, error)
|
||||
Post(url string, body []byte) ([]byte, error)
|
||||
}
|
||||
|
||||
// 领域事件接口
|
||||
type EventPublisher interface {
|
||||
Publish(topic string, message interface{}) error
|
||||
Subscribe(topic string, handler func(message []byte)) error
|
||||
}
|
||||
```
|
||||
|
||||
这些改动将显著提高代码的可测试性、可维护性和可扩展性,同时降低模块间的耦合度。
|
||||
|
||||
**Generation complete!** Please review the code suggestions above.
|
||||
397
core/循环依赖相关对话.md
Normal file
397
core/循环依赖相关对话.md
Normal file
@ -0,0 +1,397 @@
|
||||
|
||||
> 这里,我引入 github.com/phyer/core/service 为的是让 Candle struct里的 属性 core 得到正确的类型, 结果出现了 循环以来, 那么我该如何用刚才提到的依赖注入和接口隔离的方式来规避
|
||||
>
|
||||
|
||||
|
||||
🤔 Thought content:
|
||||
|
||||
|
||||
首先,我得理解问题所在。循环依赖通常发生在两个或多个包相互引用的时候。比如,如果model包引用了service包,而service包又引用了model包,就会形成循环。用户的结构体Candle有一个core字段,类型是service.Core,这可能导致model包依赖service包,而如果service包也依赖model包,就会循环。
|
||||
|
||||
接下来,用户想通过依赖注入和接口隔离来解决。依赖注入的意思是,不直接持有具体类型的实例,而是通过接口来抽象,从而解耦。接口隔离则是定义小接口,只暴露必要的方法,减少依赖。
|
||||
|
||||
我需要先检查用户的代码。在提供的代码中,Candle结构体的core字段类型是*service.Core。但用户提到引入了"github.com/phyer/core/service",这可能是指service包中的Core结构体。如果model包(即当前文件所在的包)引用了service包,而service包又引用了model包,就会形成循环。
|
||||
|
||||
解决方案应该是将core字段的类型从具体的service.Core改为一个接口类型,该接口包含Candle所需的方法。这样,model包就不再直接依赖service包,而是依赖一个本地定义的接口。service包中的Core结构体可以实现这个接口,从而解除循环依赖。
|
||||
|
||||
具体步骤可能如下:
|
||||
|
||||
1. 在model包中定义一个接口,比如CoreService,包含Candle结构体需要使用的方法。例如,如果Candle的core字段需要调用Cfg、RedisLocalCli等方法,就在接口中声明这些方法。
|
||||
|
||||
2. 将Candle结构体中的core字段类型改为这个接口类型,比如core CoreService。
|
||||
|
||||
3. 在service包中,确保Core结构体实现了model.CoreService接口的所有方法。这样,当service包导入model包时,不会有循环,因为model包现在只依赖接口,而接口在model包内部定义。
|
||||
|
||||
4. 调整代码中所有使用core字段的地方,确保通过接口方法访问,而不是直接访问结构体字段。
|
||||
|
||||
例如,用户代码中Candle结构体的core字段是*service.Core类型,改为CoreService接口类型后,循环依赖就被打破了。因为model包现在只依赖自己定义的接口,而service包实现该接口,不需要反过来引用model包中的具体类型。
|
||||
|
||||
需要检查用户提供的代码中core字段被使用的地方。例如,在SaveCandle方法中,core.Cfg.Config.Get这样的调用,说明Core结构体需要有Cfg字段。因此在CoreService接口中,可能需要一个GetCfg()方法,返回配置对象。
|
||||
|
||||
这样,model包中的代码通过接口方法访问core的功能,而不直接依赖service包的具体实现。service包中的Core结构体实现这个接口,从而解除了循环依赖。
|
||||
|
||||
最后,用户需要修改Candle结构体的core字段类型,定义接口,并调整所有使用core的地方,改为调用接口方法。这样就能避免循环依赖的问题。我们可以通过以下步骤用接口隔离和依赖注入解决循环依赖问题:
|
||||
|
||||
1. 首先在model包中定义核心服务需要的接口
|
||||
2. 修改Candle结构体使用接口类型
|
||||
3. 保持service包实现这个接口
|
||||
|
||||
具体修改如下:
|
||||
|
||||
Filepath: model/candle.go
|
||||
Replace lines: 23-26
|
||||
```go
|
||||
// 定义核心服务接口
|
||||
type CoreService interface {
|
||||
GetCfg() *simple.Json
|
||||
GetRedisLocalCli() *redis.Client
|
||||
AddToGeneralCandleChnl(candle *Candle, channels []string)
|
||||
PeriodToMinutes(period string) (int64, error)
|
||||
// 其他需要的方法...
|
||||
}
|
||||
|
||||
type Candle struct {
|
||||
Id string `json:"_id"`
|
||||
core CoreService // 改为接口类型
|
||||
InstID string `json:"instID"`
|
||||
```
|
||||
|
||||
需要确保在service包中让Core结构体实现这个接口:
|
||||
|
||||
```go
|
||||
// 在service包中
|
||||
func (c *Core) GetCfg() *simple.Json {
|
||||
return c.Cfg
|
||||
}
|
||||
|
||||
func (c *Core) GetRedisLocalCli() *redis.Client {
|
||||
return c.RedisLocalCli
|
||||
}
|
||||
|
||||
func (c *Core) AddToGeneralCandleChnl(candle *model.Candle, channels []string) {
|
||||
// 原有实现...
|
||||
}
|
||||
|
||||
func (c *Core) PeriodToMinutes(period string) (int64, error) {
|
||||
// 原有实现...
|
||||
}
|
||||
```
|
||||
|
||||
这种修改的好处:
|
||||
4. 解除了model和service包的循环依赖
|
||||
5. model包只依赖自己定义的接口
|
||||
6. service包实现model定义的接口
|
||||
7. 更容易进行单元测试(可以mock核心服务)
|
||||
8. 明确声明了依赖关系和方法契约
|
||||
|
||||
需要同步修改所有使用core字段的地方,例如:
|
||||
Filepath: model/candle.go
|
||||
Replace lines: 0-0
|
||||
```go
|
||||
core.GetCfg().Get(...)
|
||||
```
|
||||
|
||||
这样的接口隔离配合依赖注入(在创建Candle时传入实现了CoreService的对象),可以有效解决循环依赖问题。
|
||||
|
||||
---
|
||||
|
||||
- Datetime: 2025-02-21 13:48:10
|
||||
|
||||
- Model: alidsr1/deepseek-r1
|
||||
|
||||
- Selected files:
|
||||
- model/candle.go
|
||||
|
||||
- Selected code:
|
||||
|
||||
```go
|
||||
|
||||
simple "github.com/bitly/go-simplejson"
|
||||
"github.com/go-redis/redis"
|
||||
"github.com/phyer/core/service"
|
||||
"github.com/phyer/texus/utils"
|
||||
logrus "github.com/sirupsen/logrus"
|
||||
)
|
||||
```
|
||||
|
||||
> 这个model包自己定义的接口能放到util包下吗, util包不依赖任何其他包,
|
||||
|
||||
🤔 Thought content:
|
||||
|
||||
> 首先,用户提供的代码中,model包定义了几个接口,比如CoreService、Sample、SampleList,以及结构体如Candle、CandleList等。这些接口可能被其他包或model内部的结构体和方法所依赖。
|
||||
|
||||
|
||||
用户的问题是将这些接口移到util包下是否可行,同时确保util包不依赖其他包。这意味着,我需要检查这些接口是否引用了model包或其他包的类型。如果接口中的方法参数或返回值使用了model或其他包的类型,那么将这些接口移到util包会导致util包依赖这些类型所在的包,从而违反util包不依赖其他包的条件。
|
||||
|
||||
查看代码中的CoreService接口,它的方法如GetCfg()返回了*simple.Json,而simple来自"github.com/bitly/go-simplejson",这属于外部依赖。同样,GetRedisLocalCli()返回*redis.Client,来自"github.com/go-redis/redis"。还有AddToGeneralCandleChnl方法参数中有*Candle,这是model包内的类型。因此,CoreService接口依赖了外部包和model包本身,无法移到util包,因为util不能有这些依赖。
|
||||
|
||||
接下来是Sample接口,SetToKey方法参数是*CoreService,同样CoreService在model中定义,并且CoreService本身依赖了外部包。所以Sample接口也不能移到util。
|
||||
|
||||
SampleList接口中的方法返回[]*Sample,而Sample是当前包的接口,同样涉及model包的依赖。
|
||||
|
||||
因此,结论是这些接口不能移到util包,因为它们引用了model包内或外部的类型,导致util包会产生依赖。需要保持接口在model包中,或者重新设计接口以避免依赖,但这可能影响现有功能。
|
||||
|
||||
最后,向用户解释这些分析,说明原因,并建议保持接口在model包中,或者考虑其他重构方式。通过分析代码,model包中定义的接口存在以下依赖问题,无法直接移动到独立的util包:
|
||||
|
||||
9. CoreService接口依赖了其他包的组件:
|
||||
```go
|
||||
type CoreService interface {
|
||||
GetCfg() *simple.Json // 依赖github.com/bitly/go-simplejson
|
||||
GetRedisLocalCli() *redis.Client // 依赖github.com/go-redis/redis
|
||||
AddToGeneralCandleChnl(candle *Candle, channels []string) // 依赖本包Candle类型
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
10. Sample接口也依赖了本包类型:
|
||||
```go
|
||||
type Sample interface {
|
||||
SetToKey(cr *CoreService) ([]interface{}, error) // 参数依赖本包CoreService
|
||||
}
|
||||
```
|
||||
|
||||
11. SampleList接口依赖本包类型:
|
||||
```go
|
||||
type SampleList interface {
|
||||
GetSectionOf(start int, end int) ([]*Sample, error) // 返回本包Sample类型
|
||||
}
|
||||
```
|
||||
|
||||
建议方案:
|
||||
12. 保持接口定义在model包中(当前最佳方案)
|
||||
13. 如果确实需要独立util包,需要解耦依赖:
|
||||
```go
|
||||
// 需要先定义基础接口(在util包)
|
||||
type BasicService interface {
|
||||
// 只包含最基础的方法,不依赖具体实现
|
||||
}
|
||||
|
||||
// 原model包中扩展接口
|
||||
type CoreService interface {
|
||||
util.BasicService // 组合基础接口
|
||||
// 保留原项目特定方法
|
||||
}
|
||||
```
|
||||
|
||||
需要我继续提供解耦方案的具体实现代码吗?这需要对现有代码结构进行较大调整。
|
||||
|
||||
---
|
||||
|
||||
- Datetime: 2025-02-21 14:06:06
|
||||
|
||||
- Model: alidsr1/deepseek-r1
|
||||
|
||||
- Selected files:
|
||||
- core/interfaces.go
|
||||
- config/config.go
|
||||
- config/const.go
|
||||
- data/coaster.go
|
||||
- data/pixel.go
|
||||
- data/plate.go
|
||||
- data/rsi.go
|
||||
- data/segmentItem.go
|
||||
- data/series.go
|
||||
- data/shearForceGrp.go
|
||||
- data/sorted.go
|
||||
- data/tray.go
|
||||
- model/candle.go
|
||||
- model/maX.go
|
||||
- model/ticker.go
|
||||
- service/service_context.go
|
||||
- util/util.go
|
||||
- util/writeLog.go
|
||||
|
||||
- Selected code:
|
||||
|
||||
```go
|
||||
// 领域服务接口
|
||||
type CandleManager interface {
|
||||
GetCandles(instID string, period string) ([]*Candle, error)
|
||||
SaveCandle(candle *Candle) error
|
||||
}
|
||||
|
||||
// 基础设施接口
|
||||
type RedisService interface {
|
||||
GetClient(options *redis.Options) (*redis.Client, error)
|
||||
Ping(client *redis.Client) error
|
||||
}
|
||||
```
|
||||
|
||||
> 那既然model模块中定义接口, 让 service模块里的 core的struct去实现这个接口, 那么 core/interfaces.go里的接口是做什么的
|
||||
>
|
||||
|
||||
🤔 Thought content:
|
||||
让 service模块里的 core的struct去实现这个接口, 那么 core/interfaces.go里的接口是做什么的”。首先,我需要理解用户的问题背景和他们可能存在的困惑。
|
||||
|
||||
用户提到在model模块中定义了接口,并让service模块的core结构体实现这些接口,然后问core/interfaces.go中的接口的作用。我需要先看看提供的代码内容,特别是interfaces.go文件中的内容。
|
||||
|
||||
查看用户提供的core/interfaces.go文件,里面定义了多个接口,如CandleManager、RedisService、HTTPRequester、EventPublisher等。这些接口似乎是领域服务和基础设施接口的抽象。例如,CandleManager定义了获取和保存蜡烛图数据的方法,而RedisService涉及Redis客户端的获取和健康检查。
|
||||
|
||||
用户可能混淆了不同层次接口的用途。model模块中的接口可能是领域模型相关的,而core/interfaces.go中的接口可能是更上层的应用服务或基础设施接口。需要明确两者在架构中的不同角色。
|
||||
|
||||
接下来,我应该解释接口的分层设计。在六边形架构或清洁架构中,通常会有领域层、应用层和基础设施层。领域层接口定义核心业务逻辑,应用层接口定义用例,基础设施层实现具体技术细节。core/interfaces.go中的接口可能属于应用层或基础设施层,而model中的接口属于领域层。
|
||||
|
||||
需要指出core/interfaces.go中的接口作用,例如CandleManager作为领域服务接口,由service层的Core结构体实现,这样可以将业务逻辑与技术实现分离,提高可测试性和可维护性。RedisService则是基础设施接口,由具体的Redis客户端实现,遵循依赖倒置原则,允许更换底层技术而不影响上层逻辑。
|
||||
|
||||
总结时,应强调core/interfaces.go中的接口定义了服务层和基础设施的契约,而model中的接口可能更偏向领域模型,两者各司其职,共同支持系统的松耦合设计。通过分析代码结构和架构设计,可以明确不同接口的职责定位:
|
||||
|
||||
14. `core/interfaces.go` 中的接口是领域层与基础设施层的契约
|
||||
```go
|
||||
// 领域服务接口(面向业务能力)
|
||||
type CandleManager interface {
|
||||
GetCandles(instID string, period string) ([]*Candle, error)
|
||||
SaveCandle(candle *Candle) error
|
||||
}
|
||||
|
||||
// 基础设施接口(面向技术实现)
|
||||
type RedisService interface {
|
||||
GetClient(options *redis.Options) (*redis.Client, error)
|
||||
Ping(client *redis.Client) error
|
||||
}
|
||||
```
|
||||
|
||||
15. 具体实现关系示意图
|
||||
```
|
||||
┌───────────────┐ ┌───────────────┐
|
||||
│ Domain │ │ Infrastructure│
|
||||
│ (model包) │<─依赖注入 ─┤ (service包) │
|
||||
└──────┬────────┘ └──────┬────────┘
|
||||
│ │
|
||||
│ core/interfaces.go │
|
||||
│ ┌───────────────────┐ │
|
||||
└─>│ CandleManager │ │
|
||||
│ HTTPRequester │<──┘
|
||||
└───────────────────┘
|
||||
```
|
||||
|
||||
16. 关键区别说明:
|
||||
|
||||
| 维度 | model包接口 | core/interfaces.go接口 |
|
||||
|--------------------|-------------------------------------|-----------------------------------|
|
||||
| **定位** | 领域模型内部契约 | 跨层协作的抽象边界 |
|
||||
| **使用者** | 领域对象之间相互调用 | 业务服务与基础设施实现的对接点 |
|
||||
| **变化频率** | 随业务需求变化 | 随系统架构演进变化 |
|
||||
| **实现位置** | 领域层内部实现 | 基础设施层(如redis/http实现) |
|
||||
| **示例** | 如Candle实体行为 | 如RedisService定义存储访问规范 |
|
||||
|
||||
17. 设计意图解析:
|
||||
- 控制反转(IoC):通过`core/interfaces.go`定义抽象,允许service层实现具体逻辑
|
||||
- 解耦分层:领域层不直接依赖具体redis/http实现,而是通过接口抽象
|
||||
- 可测试性:Mock这些接口可以方便进行单元测试
|
||||
- 可扩展性:更换存储方案只需实现相同接口,不影响业务逻辑
|
||||
|
||||
18. 典型工作流程示例:
|
||||
```go
|
||||
// 基础设施层实现接口
|
||||
type Core struct {
|
||||
redisService RedisService // 依赖接口
|
||||
}
|
||||
|
||||
func (c *Core) GetClient(opts *redis.Options) (*redis.Client, error) {
|
||||
// 具体实现redis连接逻辑
|
||||
}
|
||||
|
||||
// 领域层通过接口使用
|
||||
func ProcessCandle(cm CandleManager) {
|
||||
cm.SaveCandle(&Candle{...}) // 实际调用Core的实现
|
||||
}
|
||||
```
|
||||
|
||||
这种设计模式遵循了SOLID原则中的:
|
||||
- 依赖倒置原则(DIP)
|
||||
- 接口隔离原则(ISP)
|
||||
- 开闭原则(OCP)
|
||||
|
||||
通过这种分层,当需要替换存储方案(如从Redis改为MySQL)时,只需实现相同的RedisService接口,而无需修改业务逻辑代码。
|
||||
|
||||
|
||||
> 也就是说, 就算Core 这个struct 里面的属性,不管有没有interface, 并不影响 model里创建 interface, 让Core struct实现model的interface, 并且绕过循环依赖的限制这件事,对吧
|
||||
|
||||
🤔 Thought content:
|
||||
|
||||
> 首先,我需要回忆Go语言中接口和结构体的关系。在Go中,接口是隐式实现的,不需要显式声明。这意味着只要Core结构体实现了model包中定义的接口的所有方法,就自动满足接口的要求,而无需在Core结构体中导入model包。
|
||||
|
||||
|
||||
接下来,用户提到的循环依赖问题。循环依赖通常发生在两个或多个包相互引用时。例如,如果model包引用了core包,而core包又引用了model包,就会导致编译错误。为了避免这种情况,可以在model包中定义接口,而core包中的结构体实现这些接口。由于core包不需要导入model包来定义结构体,只要在方法实现时正确使用接口,就可以避免循环依赖。
|
||||
|
||||
用户的问题中提到,即使Core结构体内部有其他属性,只要这些属性不涉及model包中的具体类型,就不会导致循环依赖。例如,如果Core结构体有一个Redis客户端或其他与model无关的属性,这不会影响接口的实现,因为接口只关心方法签名,而不关心结构体的内部属性。
|
||||
|
||||
我需要验证这一点。假设在model包中定义了一个CoreService接口,包含GetCfg()和GetRedisLocalCli()方法。在core包中,Core结构体实现了这些方法,即使Core结构体内部有Redis客户端或其他属性,只要这些属性的类型不来自model包,就不会导致循环依赖。这样,model包可以依赖core包中的接口实现,而core包不需要导入model包,从而打破循环依赖。
|
||||
|
||||
此外,用户提到的绕过循环依赖的关键在于接口定义和实现的方式。通过在model包中定义接口,并在core包中实现,避免了core包导入model包,从而解决了循环依赖的问题。这种方法符合Go语言的接口隐式实现特性,允许解耦包之间的依赖关系。
|
||||
|
||||
最后,我需要确认用户的理解是否正确。用户认为,即使Core结构体有其他属性,只要不直接引用model包中的具体类型,就可以实现接口并避免循环依赖。这是正确的,因为接口的实现只依赖于方法的存在,而不是结构体的内部结构。因此,用户的理解是正确的,这种设计模式可以有效解决循环依赖问题。是的,您的理解完全正确。让我们通过几个关键点来梳理这个设计思路:
|
||||
|
||||
1. **接口定义与实现解耦**:
|
||||
```go
|
||||
// model/candle.go
|
||||
package model
|
||||
|
||||
type CoreService interface {
|
||||
GetCfg() *simple.Json
|
||||
GetRedisLocalCli() *redis.Client
|
||||
// 只定义需要的方法签名
|
||||
}
|
||||
```
|
||||
|
||||
2. **Core 结构体实现**:
|
||||
```go
|
||||
// core/core.go
|
||||
package core
|
||||
|
||||
type Core struct {
|
||||
cfg *MyConfig
|
||||
redisLocalCli *redis.Client
|
||||
// 其他不涉及 model 包的字段
|
||||
}
|
||||
|
||||
// 实现接口方法(无需导入 model 包)
|
||||
func (c *Core) GetCfg() *simple.Json {
|
||||
return c.cfg.Config
|
||||
}
|
||||
|
||||
func (c *Core) GetRedisLocalCli() *redis.Client {
|
||||
return c.redisLocalCli
|
||||
}
|
||||
```
|
||||
|
||||
1. **在 model 包中的使用**:
|
||||
```go
|
||||
// model/candle.go
|
||||
func (cd *Candle) Filter(cr CoreService) bool {
|
||||
// 通过接口访问核心服务
|
||||
cfg := cr.GetCfg()
|
||||
redis := cr.GetRedisLocalCli()
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
关键优势:
|
||||
- ✅ **无循环依赖**:`core` 包不需要导入 `model` 包
|
||||
- ✅ **关注点分离**:`model` 包只定义所需行为的契约(接口)
|
||||
- ✅ **灵活实现**:`Core` 结构体可以自由添加字段(只要不直接依赖 `model` 的具体类型)
|
||||
- ✅ **隐式接口实现**:Go 的鸭子类型特性自动实现接口匹配
|
||||
|
||||
实际场景示例:
|
||||
```go
|
||||
// 在 model 包中使用
|
||||
func ProcessCandle(c CoreService, candle *Candle) {
|
||||
// 通过接口调用核心服务
|
||||
redis := c.GetRedisLocalCli()
|
||||
redis.Set("key", candle, 0)
|
||||
|
||||
cfg := c.GetCfg()
|
||||
period := cfg.Get("period").MustString()
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
这种模式的关键点在于:
|
||||
2. 接口定义方 (`model`) 不关心具体实现
|
||||
3. 实现方 (`core`) 不需要知道接口的存在
|
||||
4. 依赖方向保持单向:`model` -> `core` (通过接口)
|
||||
5. 完全解耦核心服务与领域模型
|
||||
|
||||
这种方法特别适合大型项目架构,能有效解决包循环依赖问题,同时保持代码的灵活性和可测试性。
|
||||
|
||||
**Generation complete!** Please review the code suggestions above.
|
||||
271
core/循环依赖问题.md
Normal file
271
core/循环依赖问题.md
Normal file
@ -0,0 +1,271 @@
|
||||
> 现在 service 模块下的 Core struct, 里面包含很多 比如Candle, MaX, SegemtnItem等类型的子元素, 反过来, Candle所在的model模块, 也需要引入 service 模块里的core对象, 那么就将形成 循环依赖, 我现在需要做的是 对依赖的方向进行一个确认, 比如依赖的顺序是 model单项依赖service, service单项依赖data, 我只是举个例子, 我需要做一个这样的确认, 并把每个文件放到应该放的模块中, 然后, 把某些文件中不应该放在这个文件里的函数等,移到适合的为止上去. 最后,用接口进行抽象, 把某个上游struct中,包含依赖关系中下游类型的属性
|
||||
> ,都变成接口,让下游的struct去实现接口,从而实现依赖注入防止循环依赖,
|
||||
|
||||
<think>
|
||||
好的,我需要解决用户提到的循环依赖问题。用户的主要问题是service模块下的Core结构体引用了其他模块如model、data中的类型,而这些模块又反过来引用了service模块,导致循环依赖。用户希望调整依赖方向,确保单向依赖,并通过接口抽象来解决循环引用。
|
||||
</think>
|
||||
|
||||
|
||||
首先,我需要理清当前各个模块之间的依赖关系。根据用户提供的代码,model/candle.go中的Candle结构体引用了service.Core,而service/service_context.go中的Core结构体又包含了data、model等模块的类型。这确实形成了循环依赖。
|
||||
|
||||
接下来,我需要确定一个合理的依赖方向。通常,高层模块(如service)应该依赖低层模块(如model、data),而低层模块不应依赖高层模块。因此,可以设定依赖顺序为:model → data → service。但需要检查现有代码是否符合这个方向。
|
||||
|
||||
查看代码发现,model模块中的Candle结构体引用了service.Core,这违反了低层模块不应依赖高层模块的原则。因此,需要将model模块中的service依赖移除,改为通过接口抽象。
|
||||
|
||||
解决方案是 **将Core结构体中需要被其他模块使用的方法抽象成接口** ,放在独立的包中,例如定义一个core包,包含CoreService接口。这样,model模块可以依赖core包中的接口,而service模块实现这些接口,从而打破循环依赖。
|
||||
|
||||
具体步骤可能包括:
|
||||
1. 创建新的接口包(如core),定义CoreService接口,包含其他模块需要的方法。
|
||||
2. 修改model模块中的Candle结构体,将Core字段的类型改为core.CoreService接口。
|
||||
3. 调整service模块中的Core结构体,实现core.CoreService接口。
|
||||
4. 检查其他模块如data中的类似问题,进行相应的接口抽象。
|
||||
|
||||
此外,需要将各模块中的类型移动到合适的包中,确保依赖方向正确。例如,将数据模型集中在model包,业务逻辑集中在service包,数据处理在data包。
|
||||
|
||||
在调整过程中,需要注意各个结构体之间的引用关系,确保单向依赖。例如,service模块依赖data和model,而data和model只依赖core接口,不直接引用service的具体实现。
|
||||
|
||||
最后,通过依赖注入,将接口的具体实现传递给需要的地方,如model中的Candle结构体通过接口使用Core的功能,而不直接依赖service模块。
|
||||
|
||||
这样处理后,各模块之间的依赖关系将变得清晰,避免了循环依赖,提高了代码的可维护性和可扩展性。根据代码结构和功能分析,建议按以下方案调整架构:
|
||||
|
||||
1. 依赖方向层级(单向依赖):
|
||||
```
|
||||
config → model → service → data
|
||||
↗---------------------↗
|
||||
```
|
||||
|
||||
2. 模块划分建议:
|
||||
|
||||
FILEPATH: core/interface.go(新增包)
|
||||
```go
|
||||
package core
|
||||
|
||||
import (
|
||||
"time"
|
||||
|
||||
"github.com/go-redis/redis"
|
||||
simple "github.com/bitly/go-simplejson"
|
||||
)
|
||||
|
||||
// 核心服务接口(所有依赖上层的模块都通过这个接口访问)
|
||||
type CoreService interface {
|
||||
GetConfig() *simple.Json
|
||||
GetRedisClient() *redis.Client
|
||||
PeriodToMinutes(period string) (int64, error)
|
||||
AddToGeneralCandleChnl(candle *model.Candle, channels []string)
|
||||
// 其他需要暴露的方法...
|
||||
}
|
||||
|
||||
// 数据存储接口(供service层实现)
|
||||
type DataRepository interface {
|
||||
SaveCandle(candle *model.Candle) error
|
||||
GetCandles(instID string, period string, limit int) ([]*model.Candle, error)
|
||||
// 其他数据操作方法...
|
||||
}
|
||||
|
||||
// 分析服务接口(供data层使用)
|
||||
type AnalyticsService interface {
|
||||
AnalyzeCandle(candle *model.Candle)
|
||||
GenerateReport(instID string) *data.Report
|
||||
// 其他分析功能...
|
||||
}
|
||||
```
|
||||
|
||||
1. 各模块调整建议:
|
||||
|
||||
(1)model 模块(基础数据结构):
|
||||
- 只包含领域模型定义
|
||||
- 不依赖任何其他模块
|
||||
- 示例调整:
|
||||
|
||||
FILEPATH: model/candle.go
|
||||
```go
|
||||
package model
|
||||
|
||||
import (
|
||||
"time"
|
||||
)
|
||||
|
||||
type Candle struct {
|
||||
InstID string
|
||||
Period string
|
||||
Open float64
|
||||
Close float64
|
||||
// ...其他字段
|
||||
}
|
||||
|
||||
// 所有操作都通过接口
|
||||
func (c *Candle) Process(core CoreService) {
|
||||
// 通过core接口操作
|
||||
core.AddToGeneralCandleChnl(c, []string{"channel"})
|
||||
}
|
||||
```
|
||||
|
||||
(2)data 模块(数据存储/处理):
|
||||
- 实现DataRepository接口
|
||||
- 依赖model和core接口
|
||||
- 包含:
|
||||
- data/processor.go(数据处理)
|
||||
- data/repository.go(存储实现)
|
||||
- data/coaster.go(业务数据模型)
|
||||
|
||||
(3)service 模块(业务服务):
|
||||
- 实现CoreService接口
|
||||
- 依赖model和data模块
|
||||
- 包含:
|
||||
- service/core_service.go(主服务实现)
|
||||
- service/analytics.go(分析服务)
|
||||
|
||||
(4)config 模块(配置):
|
||||
- 保持独立
|
||||
- 被所有模块依赖
|
||||
|
||||
2. 关键调整示例:
|
||||
|
||||
(1)修改service上下文:
|
||||
|
||||
FILEPATH: service/service_context.go
|
||||
```go
|
||||
package service
|
||||
|
||||
import (
|
||||
"core"
|
||||
"model"
|
||||
"data"
|
||||
)
|
||||
|
||||
type Core struct {
|
||||
// 通过组合实现接口
|
||||
core.CoreService
|
||||
core.AnalyticsService
|
||||
|
||||
// 具体实现
|
||||
dataRepo data.DataRepository
|
||||
// ...其他字段
|
||||
}
|
||||
|
||||
// 实现CoreService接口
|
||||
func (c *Core) GetConfig() *simple.Json {
|
||||
return c.config.GetConfigJson()
|
||||
}
|
||||
|
||||
// 实现DataRepository接口
|
||||
func (c *Core) SaveCandle(candle *model.Candle) error {
|
||||
return c.dataRepo.Save(candle)
|
||||
}
|
||||
```
|
||||
|
||||
(2)调整data层:
|
||||
|
||||
FILEPATH: data/processor.go
|
||||
```go
|
||||
package data
|
||||
|
||||
import (
|
||||
"core"
|
||||
"model"
|
||||
)
|
||||
|
||||
type CandleProcessor struct {
|
||||
analytics core.AnalyticsService
|
||||
}
|
||||
|
||||
func NewProcessor(a core.AnalyticsService) *CandleProcessor {
|
||||
return &CandleProcessor{analytics: a}
|
||||
}
|
||||
|
||||
func (p *CandleProcessor) Process(c *model.Candle) {
|
||||
// 使用接口进行数据分析
|
||||
p.analytics.AnalyzeCandle(c)
|
||||
}
|
||||
```
|
||||
|
||||
3. 文件移动建议:
|
||||
|
||||
(1)将原data/shearForceGrp.go、data/series.go 移动到 service/ 下,属于业务逻辑
|
||||
|
||||
(2)将原model/maX.go 移动到 data/,属于数据处理
|
||||
|
||||
4. 最终依赖关系:
|
||||
```
|
||||
config → model → data → service
|
||||
↑ ↖ core ↗
|
||||
└------------┘
|
||||
```
|
||||
|
||||
这个架构调整后:
|
||||
|
||||
5. 所有具体实现都面向接口编程
|
||||
6. 上层模块(service)依赖下层模块(data/model)
|
||||
7. 核心接口定义在core包供各方依赖
|
||||
8. 每个模块的职责更清晰:
|
||||
- model:纯数据结构
|
||||
- data:数据存储和处理
|
||||
- service:业务逻辑
|
||||
- core:接口定义
|
||||
|
||||
需要进行的*SEARCH/REPLACE*修改示例:
|
||||
|
||||
(1)修改Candle结构定义:
|
||||
|
||||
FILEPATH: model/candle.go
|
||||
```go
|
||||
Filepath:
|
||||
<SEARCH>
|
||||
type Candle struct {
|
||||
Id string `json:"_id"`
|
||||
Core CoreService // 改为接口类型
|
||||
InstID string `json:"instID"`
|
||||
type Candle struct {
|
||||
Id string `json:"_id"`
|
||||
Processor core.CandleProcessor // 通过接口访问
|
||||
InstID string `json:"instID"`
|
||||
```
|
||||
```
|
||||
|
||||
(2)调整service核心结构:
|
||||
|
||||
FILEPATH: service/service_context.go
|
||||
```go
|
||||
Filepath:
|
||||
|
||||
**Generation complete!** Please review the code suggestions above.
|
||||
|
||||
```
|
||||
|
||||
|
||||
## 关键重构点说明:
|
||||
|
||||
1. 依赖方向调整:
|
||||
```
|
||||
config → model → data → service
|
||||
↗ ↖
|
||||
core ←──────┘
|
||||
```
|
||||
|
||||
2. 接口定义全部提升到core包,包括:
|
||||
- 核心服务接口(CoreService)
|
||||
- 数据操作接口(CandleManager)
|
||||
- Redis服务接口(RedisService)
|
||||
- 时间段服务接口(SegmentService)
|
||||
|
||||
1. 具体实现:
|
||||
- model:只包含数据结构和基础验证
|
||||
- data:实现数据存储相关逻辑
|
||||
- service:实现业务逻辑和服务组合
|
||||
- config:配置加载保持独立
|
||||
|
||||
2. 依赖注入:
|
||||
- 通过构造函数显式注入依赖
|
||||
- 上层模块依赖下层接口而非实现
|
||||
- 核心接口定义统一在core包
|
||||
|
||||
需要继续完善的工作:
|
||||
|
||||
3. 逐步替换所有具体类型引用为接口类型
|
||||
4. 使用依赖注入框架管理组件生命周期
|
||||
5. 添加接口的Mock实现用于单元测试
|
||||
6. 统一异常处理规范
|
||||
7. 增加领域事件机制
|
||||
|
||||
|
||||
2
demo/三个运动定律.md
Normal file
2
demo/三个运动定律.md
Normal file
@ -0,0 +1,2 @@
|
||||
|
||||
运动定律是艾萨克·牛顿 (Isaac Newton) 提出的三个定律,它们描述了物体的运动与作用在其上的力之间的关系。
|
||||
0
exhange.go.md
Normal file
0
exhange.go.md
Normal file
0
freqtrade.md
Normal file
0
freqtrade.md
Normal file
241
freqtrade_基础.md
Normal file
241
freqtrade_基础.md
Normal file
@ -0,0 +1,241 @@
|
||||
帮我讲解一下下面的内容,没太看明白
|
||||
|
||||
|
||||
|
||||
```
|
||||
Bot execution logic¶Starting freqtrade in dry-run or live mode (using freqtrade trade) will start the bot and start the bot iteration loop. This will also run the bot_start() callback.By default, the bot loop runs every few seconds (internals.process_throttle_secs) and performs the following actions:
|
||||
``
|
||||
Fetch open trades from persistence.
|
||||
Calculate current list of tradable pairs.
|
||||
Download OHLCV data for the pairlist including all informative pairs
|
||||
This step is only executed once per Candle to avoid unnecessary network traffic.
|
||||
Call bot_loop_start() strategy callback.
|
||||
Analyze strategy per pair.
|
||||
Call populate_indicators()
|
||||
Call populate_entry_trend()
|
||||
Call populate_exit_trend()
|
||||
Update trades open order state from exchange.
|
||||
Call order_filled() strategy callback for filled orders.
|
||||
Check timeouts for open orders.
|
||||
Calls check_entry_timeout() strategy callback for open entry orders.
|
||||
Calls check_exit_timeout() strategy callback for open exit orders.
|
||||
Calls adjust_order_price() strategy callback for open orders.
|
||||
Calls adjust_entry_price() strategy callback for open entry orders. only called when adjust_order_price() is not implemented
|
||||
Calls adjust_exit_price() strategy callback for open exit orders. only called when adjust_order_price() is not implemented
|
||||
Verifies existing positions and eventually places exit orders.
|
||||
Considers stoploss, ROI and exit-signal, custom_exit() and custom_stoploss().
|
||||
Determine exit-price based on exit_pricing configuration setting or by using the custom_exit_price() callback.
|
||||
Before an exit order is placed, confirm_trade_exit() strategy callback is called.
|
||||
Check position adjustments for open trades if enabled by calling adjust_trade_position() and place additional order if required.
|
||||
Check if trade-slots are still available (if max_open_trades is reached).
|
||||
Verifies entry signal trying to enter new positions.
|
||||
Determine entry-price based on entry_pricing configuration setting, or by using the custom_entry_price() callback.
|
||||
In Margin and Futures mode, leverage() strategy callback is called to determine the desired leverage.
|
||||
Determine stake size by calling the custom_stake_amount() callback.
|
||||
Before an entry order is placed, confirm_trade_entry() strategy callback is called.
|
||||
```
|
||||
|
||||
|
||||
这段内容是 Freqtrade 官方文档中关于“机器人执行逻辑”(Bot Execution Logic)的描述,主要讲解了 Freqtrade 交易机器人在启动后(无论是模拟模式 Dry-run 还是实盘模式 Live mode)如何通过一个循环(Bot Iteration Loop)持续运行并执行交易相关的操作。你的困惑可能来自于专业术语较多或逻辑流程不够直观,下面我会尽量用通俗的语言一步步拆解这段内容。
|
||||
|
||||
---
|
||||
|
||||
核心概念
|
||||
|
||||
Freqtrade 的机器人并不是一次性执行完所有任务后就停止,而是像一个“永动机”一样,每隔几秒(由 internals.process_throttle_secs 参数控制,默认为几秒钟)运行一次完整的逻辑循环。这个循环会检查市场、更新交易状态、执行买卖操作,直到你手动停止机器人。
|
||||
|
||||
启动机器人时(用命令 freqtrade trade),会触发以下流程:
|
||||
|
||||
1. 初始化: 调用 bot_start() 回调函数(如果你在策略中定义了这个函数,它会在机器人启动时执行一次)。
|
||||
|
||||
2. 进入循环: 每隔几秒执行一次完整的逻辑。
|
||||
|
||||
|
||||
---
|
||||
|
||||
循环中的每一步
|
||||
|
||||
下面是循环中每次迭代的具体步骤,我会逐一解释它们的含义和作用:
|
||||
|
||||
1. 从持久化存储中获取未关闭的交易
|
||||
|
||||
- 含义: 检查当前有哪些交易(比如已经买入但还没卖出的订单)还在进行中。
|
||||
|
||||
- 作用: 确保机器人知道当前的交易状态,避免重复操作或遗漏已有交易。
|
||||
|
||||
- 举例: 你昨天买了 BTC/USD,今天机器人启动后会先加载这些未卖出的交易。
|
||||
|
||||
|
||||
2. 计算当前可交易的货币对列表
|
||||
|
||||
- 含义: 根据你的配置(pairlist,交易对列表),确定当前可以交易的货币对(比如 BTC/USD、ETH/USD)。
|
||||
|
||||
- 作用: 动态更新交易对,可能剔除流动性差的或添加新的交易对。
|
||||
|
||||
- 你的背景: 类似你在 Go/Node.js 中动态管理 API 请求的目标列表。
|
||||
|
||||
|
||||
3. 下载 OHLCV 数据
|
||||
|
||||
- 含义: OHLCV 是指“开盘价、最高价、最低价、收盘价、成交量”的数据,用于分析市场走势。
|
||||
|
||||
- 细节:
|
||||
|
||||
- 只针对配置中的交易对和“信息对”(informative pairs,可能用于辅助决策的额外数据)。
|
||||
|
||||
- 为了减少网络请求,每根K线(比如 1小时K线)只下载一次。
|
||||
|
||||
- 作用: 为后续策略分析提供最新的市场数据。
|
||||
|
||||
- 举例: 下载了过去 1 小时 BTC/USD 的价格数据。
|
||||
|
||||
|
||||
4. 调用 bot_loop_start() 回调
|
||||
|
||||
- 含义: 如果你在策略中定义了这个函数,它会在每次循环开始时运行。
|
||||
|
||||
- 作用: 让你插入自定义逻辑,比如打印日志或检查外部条件。
|
||||
|
||||
- 举例: 你可以用它记录每次循环的时间。
|
||||
|
||||
|
||||
5. 逐个分析交易对的策略
|
||||
|
||||
- 含义: 对每个交易对运行你的策略代码,分三步调用:
|
||||
|
||||
1. populate_indicators(): 计算技术指标(如均线、RSI)。
|
||||
|
||||
2. populate_entry_trend(): 判断是否应该买入(进场信号)。
|
||||
|
||||
3. populate_exit_trend(): 判断是否应该卖出(离场信号)。
|
||||
|
||||
- 作用: 这是策略的核心,决定买卖的时机。
|
||||
|
||||
- 举例: 如果 BTC/USD 的价格高于 20 日均线,可能触发买入信号。
|
||||
|
||||
|
||||
6. 从交易所更新交易和订单状态
|
||||
|
||||
- 含义: 检查当前订单的状态(比如是否已成交、是否超时)。
|
||||
|
||||
- 细节:
|
||||
|
||||
- 如果订单已成交,调用 order_filled() 回调。
|
||||
|
||||
- 检查未成交订单是否超时:
|
||||
|
||||
- 买入订单超时调用 check_entry_timeout()。
|
||||
|
||||
- 卖出订单超时调用 check_exit_timeout()。
|
||||
|
||||
- 调整订单价格(如果需要):
|
||||
|
||||
- 调用 adjust_order_price(),如果没实现则分别调用 adjust_entry_price()(买入)和 adjust_exit_price()(卖出)。
|
||||
|
||||
- 作用: 确保订单状态与交易所一致,避免错过成交或长时间挂单。
|
||||
|
||||
- 举例: 你下的买入订单 1 小时没成交,机器人可能会取消它。
|
||||
|
||||
|
||||
7. 检查现有仓位并决定是否卖出
|
||||
|
||||
- 含义: 检查当前持有的仓位(已买入但未卖出的交易),决定是否需要卖出。
|
||||
|
||||
- 细节:
|
||||
|
||||
- 考虑止损(stoploss)、投资回报率(ROI)、卖出信号(exit-signal)等。
|
||||
|
||||
- 可通过 custom_exit() 或 custom_stoploss() 自定义卖出逻辑。
|
||||
|
||||
- 卖出价格由配置中的 exit_pricing 或 custom_exit_price() 决定。
|
||||
|
||||
- 卖出前调用 confirm_trade_exit() 确认。
|
||||
|
||||
- 作用: 自动执行卖出操作,比如达到盈利目标或触发止损。
|
||||
|
||||
- 举例: BTC/USD 涨了 5%,达到 ROI,机器人自动卖出。
|
||||
|
||||
|
||||
8. 调整现有交易的仓位
|
||||
|
||||
- 含义: 如果开启了仓位调整功能,调用 adjust_trade_position() 检查是否需要加仓或减仓。
|
||||
|
||||
- 作用: 动态管理仓位,比如在盈利时加仓。
|
||||
|
||||
- 举例: BTC/USD 涨了 3%,你决定再投入一部分资金。
|
||||
|
||||
|
||||
9. 检查交易槽位是否可用
|
||||
|
||||
- 含义: 检查是否达到最大同时交易数量(max_open_trades)。
|
||||
|
||||
- 作用: 避免超过设定的交易上限。
|
||||
|
||||
- 举例: 如果上限是 5 个交易,而已有 5 个未关闭,就不会开新仓。
|
||||
|
||||
|
||||
10. 验证买入信号并开新仓
|
||||
|
||||
- 含义: 如果有买入信号(由 populate_entry_trend() 生成),决定是否下单买入。
|
||||
|
||||
- 细节:
|
||||
|
||||
- 买入价格由 entry_pricing 配置或 custom_entry_price() 决定。
|
||||
|
||||
- 在杠杆模式(Margin/Futures)下,调用 leverage() 确定杠杆倍数。
|
||||
|
||||
- 调用 custom_stake_amount() 确定投入金额。
|
||||
|
||||
- 买入前调用 confirm_trade_entry() 确认。
|
||||
|
||||
- 作用: 执行买入操作,开新仓。
|
||||
|
||||
- 举例: ETH/USD 触发买入信号,机器人以市价买入 0.1 ETH。
|
||||
|
||||
|
||||
11. 重复循环
|
||||
|
||||
- 上述步骤完成后,机器人等待几秒(process_throttle_secs),然后重新开始循环,直到你停止它。
|
||||
|
||||
|
||||
---
|
||||
|
||||
用生活化的比喻理解
|
||||
|
||||
想象 Freqtrade 是一个“超市收银员”,每隔几秒检查一次:
|
||||
|
||||
1. 看看手头的单子(获取未关闭交易)。
|
||||
|
||||
2. 更新商品清单(计算交易对列表)。
|
||||
|
||||
3. 拿最新的价格表(下载 OHLCV 数据)。
|
||||
|
||||
4. 喊一声开工(bot_loop_start())。
|
||||
|
||||
5. 分析每个商品是否值得买或卖(策略分析)。
|
||||
|
||||
6. 确认订单状态(更新交易所数据)。
|
||||
|
||||
7. 决定卖掉手里的货(检查仓位并卖出)。
|
||||
|
||||
8. 调整购物篮里的东西(调整仓位)。
|
||||
|
||||
9. 看看还能不能再买(检查交易槽位)。
|
||||
|
||||
10. 发现好货就下单(执行买入)。 然后重复这个过程,像一个勤劳的机器人收银员。
|
||||
|
||||
|
||||
---
|
||||
|
||||
对你的背景的适应
|
||||
|
||||
- Go/Node.js 经验: 这个循环类似于事件驱动编程(Event Loop),每次迭代处理一堆任务。你可以把回调函数(callback)看作异步任务的处理器。
|
||||
|
||||
- Linux 运维经验: 你可以轻松管理 Freqtrade 的日志(user_data/log)、进程(用 ps 或 docker ps 查看),甚至写脚本监控性能。
|
||||
|
||||
|
||||
---
|
||||
|
||||
如果还有疑问
|
||||
|
||||
- 你没看明白的具体是哪部分?是回调函数的作用,还是某个步骤的逻辑?告诉我,我再深入讲解!
|
||||
5
freqtrade_理解消化.md
Normal file
5
freqtrade_理解消化.md
Normal file
@ -0,0 +1,5 @@
|
||||
|
||||
[populate_indicators函数](populate_indicators函数)
|
||||
|
||||
问题列表:
|
||||
1. 既然是freqtrade调用populate_indicators,那么OHLCV在哪儿,又是怎么计算成不同timeframe的指标的,比如我有12个币对,12个timeframe,然后我关注n种类型的指标,怎么安排计算这144*n个指标,计算完了如何存放是否要进行数据持久化,或者所谓的落盘。
|
||||
73
n8n/Getting_started.md
Normal file
73
n8n/Getting_started.md
Normal file
@ -0,0 +1,73 @@
|
||||
https://docs.n8n.io/learning-path/
|
||||
|
||||
这是一篇n8n入门指南,涵盖社区交流、注册安装、试用学习、自主搭建等多方面内容,帮助用户快速上手n8n: 1. **社区互动**:n8n社区活跃,用户可在社区论坛提问、提需求,在GitHub上报Bug、做贡献。 2. **注册与安装**:尚无账号的用户,可在n8n Cloud注册免费试用,或用Docker(推荐)、npm安装社区版,详情可查看“Choose your n8n” 。 3. **试用体验**:新手可通过快速入门指南搭建基础工作流程,包括超快速入门、详细入门教程,还有构建AI工作流程的指引 。 4. **课程学习**:n8n提供视频课程和文本课程。视频课程分为初学者和高级课程,分别讲解基础和复杂功能;文本课程分初、中级,用户学习同时构建复杂工作流程,还能获得徽章和头像。 5. **自主搭建**:探索n8n的多种自托管选项,热门方案有在DigitalOcean和亚马逊云服务上进行搭建 。 6. **自定义节点**:若找不到特定应用或服务的节点,用户可自行构建并分享。可参考npm网站他人成果,学习构建声明式节点和自定义节点(YouTube视频教程) 。 7. **资讯关注**:通过版本说明了解新功能和Bug修复情况,还可在Twitter/X、Discord等社交平台关注n8n 。
|
||||
|
||||
![[Pasted image 20250204021453.png]]
|
||||
|
||||
- - 新手引导概述
|
||||
|
||||
- 本指南助力用户开启n8n学习之旅
|
||||
|
||||
- 可依需求选择相关学习内容
|
||||
|
||||
- 社区互动渠道
|
||||
|
||||
- 在社区论坛提问和提功能需求
|
||||
|
||||
- 在GitHub上报Bug和贡献代码
|
||||
|
||||
- 搭建n8n环境
|
||||
|
||||
- 注册n8n Cloud免费试用账号
|
||||
|
||||
- 用Docker或npm安装社区版
|
||||
|
||||
- 上手体验操作
|
||||
|
||||
- 通过快速入门指南搭建基础流程
|
||||
|
||||
- 尝试搭建AI工作流程
|
||||
|
||||
- 课程学习资源
|
||||
|
||||
- 视频课程涵盖初高级知识要点
|
||||
|
||||
- 文本课程边学边搭建复杂流程
|
||||
|
||||
- 自主搭建方案
|
||||
|
||||
- 在DigitalOcean上托管n8n
|
||||
|
||||
- 在亚马逊云服务上托管n8n
|
||||
|
||||
- 自定义节点构建
|
||||
|
||||
- 自行构建节点并分享给社区
|
||||
|
||||
- 学习构建声明式风格的节点
|
||||
|
||||
- 关注更新动态
|
||||
|
||||
- 从发布说明了解新功能和修复
|
||||
|
||||
- 在多平台关注n8n官方动态
|
||||
|
||||
|
||||
## 学习路径
|
||||
|
||||
https://docs.n8n.io/learning-path/#set-up-your-n8n
|
||||
|
||||
这是n8n的新手引导网页,为用户提供了入门教程和资源,帮助其快速上手使用n8n。
|
||||
1. **社区支持**:n8n社区活跃,用户能在社区论坛提问、提功能需求,也可在GitHub上报Bug和贡献代码。
|
||||
2. **基础准备**:没有账号的用户,可以注册n8n Cloud免费试用版,或用Docker(推荐) 、npm安装社区版。
|
||||
3. **快速上手**:通过快速入门指南搭建基础工作流,有“非常快速的快速入门”“较长的介绍”以及“在n8n中构建AI工作流”等内容。
|
||||
4. **课程学习**:包含视频课程和文本课程。视频课程分初级和高级,分别涵盖n8n基础及复杂工作流等内容;
|
||||
- The [Beginner](https://www.youtube.com/playlist?list=PLlET0GsrLUL59YbxstZE71WszP3pVnZfI) course covers the basics of n8n.
|
||||
- The [Advanced](https://www.youtube.com/playlist?list=PLlET0GsrLUL5bxmx5c1H1Ms_OtOPYZIEG) course covers more complex workflows, more technical nodes, and enterprise features
|
||||
6. 文本课程可在构建复杂工作流同时学习关键概念,完成还能获徽章和头像。
|
||||
- [Level 1: Beginner Course](https://blog.n8n.io/announcing-the-n8n-certification-course-for-beginners-level-1/)
|
||||
- [Level 2: Intermediate Course](https://blog.n8n.io/announcing-course-level-two/)
|
||||
7. **自主托管**:可探索多种自托管选项,热门选择有在DigitalOcean和亚马逊云服务上托管。
|
||||
8. **节点构建**:若找不到特定应用或服务的节点,可自行构建并分享,还能参考npm网站上他人的成果。
|
||||
9. **动态关注**:通过版本说明了解新功能和Bug修复情况,还能在Twitter/X、Discord等社交平台关注n8n。
|
||||
![[Pasted image 20250204022601.png]]
|
||||
28
n8n/如何触发.md
Normal file
28
n8n/如何触发.md
Normal file
@ -0,0 +1,28 @@
|
||||
|
||||
obsidian://open?vault=myNotes&file=n8n%2FGetting%20started
|
||||
1[asdf](obsidian://open?vault=myNotes&file=n8n%2FGetting%20started)
|
||||
|
||||
n8n中某个workflow的触发条件主要有以下几种:
|
||||
|
||||
1. **时间触发**
|
||||
|
||||
- **定时任务触发**:可通过Cron节点或Interval节点实现。Cron节点能按照Cron表达式设定特定时间规则来触发,如每天凌晨2点执行,表达式为`0 0 2 * * *`。Interval节点则按固定时间间隔触发,比如每15分钟触发一次,可用于定时检查数据更新等任务。
|
||||
|
||||
- **特定时间点触发**:结合时间相关节点和逻辑判断,设置在某个具体时间点触发工作流,如在特定日期的某个时刻执行数据备份操作。
|
||||
-
|
||||
|
||||
2. **事件触发**
|
||||
|
||||
- **Webhook触发**:当外部系统发生特定事件时,通过向n8n发送Webhook请求来触发工作流。例如,在GitHub中创建了新的Issue或合并了Pull Request时,GitHub可向n8n配置的Webhook地址发送通知,从而触发相应的工作流来进行后续处理。
|
||||
|
||||
- **应用程序事件触发**:n8n连接的应用程序产生特定事件时触发,像ClickUp中创建新任务,可利用ClickUp的触发节点,当有新任务创建事件发生,就会触发关联的n8n工作流。
|
||||
|
||||
- **消息触发**:在即时通讯工具等应用场景中,收到特定消息或特定用户发送的消息时可触发工作流。如在Slack中收到特定关键词的消息,通过Slack节点监听消息事件来触发工作流进行自动回复等操作。
|
||||
|
||||
3. **数据变化触发**
|
||||
|
||||
- **数据更新触发**:当连接的数据库、文件存储等数据源中的数据发生更新、插入或删除操作时触发。以MySQL数据库为例,可通过数据库节点监听数据变化,若某张表有新数据插入,就触发工作流进行数据同步或分析。
|
||||
|
||||
- **数据符合特定条件触发**:结合数据处理节点和条件判断节点,当数据满足特定条件时触发。如从Google Sheets获取数据,通过函数节点判断数据是否达到某个阈值,若达到则触发后续工作流进行预警等操作。
|
||||
|
||||
4. **手动触发**:在n8n界面中,可通过点击“Test Workflow”等按钮手动触发工作流,方便在开发、测试阶段或者有特殊需求时,即时执行工作流进行调试或数据处理。
|
||||
0
populate_indicator.md
Normal file
0
populate_indicator.md
Normal file
0
populate_indicators.md
Normal file
0
populate_indicators.md
Normal file
12
populate_indicators函数.md
Normal file
12
populate_indicators函数.md
Normal file
@ -0,0 +1,12 @@
|
||||
|
||||
|
||||
```python
|
||||
# 1. 计算指标
|
||||
def populate_indicators(self, dataframe: pd.DataFrame, metadata: dict) -> pd.DataFrame:
|
||||
# 计算 20 周期指数均线
|
||||
dataframe['ema20'] = dataframe['close'].ewm(span=20, adjust=False).mean()
|
||||
return dataframe
|
||||
```
|
||||
|
||||
参数:这里的参数
|
||||
1. self:
|
||||
7
templates/阅读笔记.md
Normal file
7
templates/阅读笔记.md
Normal file
@ -0,0 +1,7 @@
|
||||
---
|
||||
date:
|
||||
describe:
|
||||
tags:
|
||||
from link:
|
||||
---
|
||||
|
||||
16
可以用到的vim语法试试.md
Normal file
16
可以用到的vim语法试试.md
Normal file
@ -0,0 +1,16 @@
|
||||
---
|
||||
date:
|
||||
describe:
|
||||
tags:
|
||||
from link:
|
||||
---
|
||||
以下这些命令都可以用:
|
||||
```
|
||||
ggdG
|
||||
dd
|
||||
%s/ab/cd/g
|
||||
|
||||
```
|
||||
|
||||
|
||||
|
||||
11
学英语/insert into redis.md
Normal file
11
学英语/insert into redis.md
Normal file
@ -0,0 +1,11 @@
|
||||
写一个go文件, trans.go, 读取 ./output.csv, 此文件内容类似:
|
||||
Grade,Book,Version,Unit,Lesson,Word,Pronunciation,Translation
|
||||
1,人教新起点一年级上册英语,人教版,Unit 1,MY NUMBERS (L1-3),,,
|
||||
1,人教新起点一年级上册英语,人教版,Unit 1,MY NUMBERS (L1-3),door,门 /dɔ:(r)/,door
|
||||
...
|
||||
|
||||
一共有几十万行, 6.3个G,文件很大,请优化代码,
|
||||
把从第二行开始的每一行, 写进redis, key为 : word|${version}|${$word}, value为 ${Grade}|${Book}|${Version}|${Unit}|${Lesson}|${Word}|${Pronunciation}|${Translation}
|
||||
|
||||
redis地址为 10.71.142.84:6379, dbNumber使用1
|
||||
|
||||
56
学英语/请提供给我小学五年级之前应会的英语单词列表, 包括动词,名词,形容词,副词等等.md
Normal file
56
学英语/请提供给我小学五年级之前应会的英语单词列表, 包括动词,名词,形容词,副词等等.md
Normal file
@ -0,0 +1,56 @@
|
||||
|
||||
以下是小学五年级之前应会的英语单词列表:
|
||||
|
||||
|
||||
|
||||
### 名词
|
||||
|
||||
- **学习用品**:school(学校)、book(书)、pencil(铅笔)、ruler(尺子)、eraser(橡皮)、notebook(笔记本)
|
||||
|
||||
- **家庭成员**:father(爸爸)、mother(妈妈)、brother(哥哥;弟弟)、sister(姐姐;妹妹)、uncle(叔叔;舅舅)、aunt(阿姨;姑姑)
|
||||
|
||||
- **颜色**:red(红色)、blue(蓝色)、green(绿色)、yellow(黄色)、black(黑色)、white(白色)
|
||||
|
||||
- **动物**:cat(猫)、dog(狗)、pig(猪)、duck(鸭)、rabbit(兔子)、bird(鸟)
|
||||
|
||||
- **食物饮料**:rice(米饭)、bread(面包)、milk(牛奶)、water(水)、apple(苹果)、banana(香蕉)
|
||||
|
||||
- **时间日期**:year(年)、month(月)、week(周)、day(天)、morning(早上)、afternoon(下午)
|
||||
|
||||
- **地点场所**:home(家)、school(学校)、park(公园)、library(图书馆)、hospital(医院)
|
||||
|
||||
- **交通工具**:car(汽车)、bus(公共汽车)、bike(自行车)、train(火车)、plane(飞机)
|
||||
|
||||
|
||||
|
||||
### 动词
|
||||
|
||||
- **行为动作**:go(去;走)、come(来)、run(跑)、jump(跳)、swim(游泳)、fly(飞;放)
|
||||
|
||||
- **感官动词**:see(看见)、hear(听见)、look(看)、listen(听)、taste(尝起来)、smell(闻起来)
|
||||
|
||||
- **其他动词**:have(有;吃;喝)、do(做;干)、make(制作;做)、like(喜欢)、love(爱;喜爱)、want(想要)、give(给)
|
||||
|
||||
|
||||
|
||||
### 形容词
|
||||
|
||||
- **描述事物特征**:big(大的)、small(小的)、long(长的)、short(短的;矮的)、tall(高的)、fat(胖的)
|
||||
|
||||
- **描述人物特征**:happy(高兴的)、sad(难过的)、angry(生气的)、tired(累的)、clever(聪明的)、kind(和蔼的)
|
||||
|
||||
- **描述天气**:sunny(晴朗的)、cloudy(多云的)、windy(有风的)、rainy(下雨的)、snowy(下雪的)
|
||||
|
||||
- **其他**:good(好的)、bad(坏的)、new(新的)、old(旧的;老的)、right(正确的)、wrong(错误的)
|
||||
|
||||
|
||||
|
||||
### 副词
|
||||
|
||||
- **时间副词**:now(现在)、then(那时)、today(今天)、tomorrow(明天)、yesterday(昨天)、soon(很快)
|
||||
|
||||
- **频率副词**:always(总是)、usually(通常)、often(经常)、sometimes(有时)、never(从不)
|
||||
|
||||
- **程度副词**:very(非常)、much(很;非常)、too(太;也)、so(如此;这么)、quite(相当)
|
||||
|
||||
- **方式副词**:slowly(慢慢地)、quickly(快速地)、carefully(仔细地)、happily(高兴地)、loudly(大声地)
|
||||
426
学英语/高中英语词汇.md
Normal file
426
学英语/高中英语词汇.md
Normal file
@ -0,0 +1,426 @@
|
||||
|
||||
|单元|单词|词性|中文释义|
|
||||
|
||||
|---|---|---|---|
|
||||
|
||||
|必修1 Unit 1|survey|n.|调查;测验|
|
||||
|
||||
|必修1 Unit 1|add up| |合计|
|
||||
|
||||
|必修1 Unit 1|upset|adj.;vt.|心烦意乱的;不安的;不适的;使不安;使心烦|
|
||||
|
||||
|必修1 Unit 1|ignore|vt.|不理睬;忽视|
|
||||
|
||||
|必修1 Unit 1|calm|vt.;vi.;adj.|(使)平静;(使)镇定;平静的;镇静的;沉着的|
|
||||
|
||||
|必修1 Unit 1|calm(...)down| |(使)平静下来;(使)镇定下来|
|
||||
|
||||
|必修1 Unit 1|have got to| |不得不;必须|
|
||||
|
||||
|必修1 Unit 1|concern|n.;vt.|担心;关注;(利害)关系;(使)担忧;涉及;关系到|
|
||||
|
||||
|必修1 Unit 1|be concerned about| |关心;挂念|
|
||||
|
||||
|必修1 Unit 1|walk the dog| |遛狗|
|
||||
|
||||
|必修1 Unit 1|loose|adj.|松的;松开的|
|
||||
|
||||
|必修1 Unit 1|vet|n.|兽医|
|
||||
|
||||
|必修1 Unit 1|go through| |经历;经受|
|
||||
|
||||
|必修1 Unit 1|Amsterdam|n.|阿姆斯特丹(荷兰首都)|
|
||||
|
||||
|必修1 Unit 1|Netherlands|n.|荷兰(西欧国家)|
|
||||
|
||||
|必修1 Unit 1|Jewish|adj.|犹太人的;犹太族的|
|
||||
|
||||
|必修1 Unit 1|German|n.;adj.|德国人;德语;德国的;德国人的;德语的|
|
||||
|
||||
|必修1 Unit 1|Nazi|n.;adj.|纳粹党人;纳粹党的|
|
||||
|
||||
|必修1 Unit 1|set down| |记下;放下;登记|
|
||||
|
||||
|必修1 Unit 1|series|n.|连续;系列|
|
||||
|
||||
|必修1 Unit 1|a series of| |一连串的;一系列;一套|
|
||||
|
||||
|必修1 Unit 1|Kitty|n.|基蒂(女名)|
|
||||
|
||||
|必修1 Unit 1|outdoors|adv.|在户外;在野外|
|
||||
|
||||
|必修1 Unit 1|spellbind|vt.|迷住;迷惑|
|
||||
|
||||
|必修1 Unit 1|on purpose| |故意|
|
||||
|
||||
|必修1 Unit 1|in order to| |为了……|
|
||||
|
||||
|必修1 Unit 1|dusk|n.|黄昏;傍晚|
|
||||
|
||||
|必修1 Unit 1|at dusk| |在黄昏时刻|
|
||||
|
||||
|必修1 Unit 1|thunder|n.;vi.|雷;雷声;打雷;雷鸣|
|
||||
|
||||
|必修1 Unit 1|entire|adj.|整个的;完全的;全部的|
|
||||
|
||||
|必修1 Unit 1|entirely|adv.|完全地;全然地;整个地|
|
||||
|
||||
|必修1 Unit 1|power|n.|能力;力量;权力|
|
||||
|
||||
|必修1 Unit 1|face to face| |面对面地|
|
||||
|
||||
|必修1 Unit 1|curtain|n.|窗帘;门帘;幕布|
|
||||
|
||||
|必修1 Unit 1|dusty|adj.|积满灰尘的|
|
||||
|
||||
|必修1 Unit 1|no longer/not...any longer| |不再……|
|
||||
|
||||
|必修1 Unit 1|partner|n.|伙伴;合作者;合伙人|
|
||||
|
||||
|必修1 Unit 1|settle|vi.;vt.|安家;定居;停留;使定居;安排;解决|
|
||||
|
||||
|必修1 Unit 1|suffer|vt.;vi.|遭受;忍受;经历|
|
||||
|
||||
|必修1 Unit 1|suffer from| |遭受;患病|
|
||||
|
||||
|必修1 Unit 1|loneliness|n.|孤单;寂寞|
|
||||
|
||||
|必修1 Unit 1|highway|n.|公路;大路|
|
||||
|
||||
|必修1 Unit 1|recover|vi.;vt.|痊愈;恢复;重新获得|
|
||||
|
||||
|必修1 Unit 1|get/be tired of| |对……厌烦|
|
||||
|
||||
|必修1 Unit 1|pack|n.;vi.;vt.|小包;包裹;捆扎;包装;打行李|
|
||||
|
||||
|必修1 Unit 1|pack (sth) up| |将(东西)装箱打包|
|
||||
|
||||
|必修1 Unit 1|suitcase|n.|手提箱;衣箱|
|
||||
|
||||
|必修1 Unit 1|Margot|n.|玛戈(女名)|
|
||||
|
||||
|必修1 Unit 1|Overcoat|n.|大衣;外套|
|
||||
|
||||
|必修1 Unit 1|teenager|n.|十几岁的青少年|
|
||||
|
||||
|必修1 Unit 1|get along with| |与……相处;进展|
|
||||
|
||||
|必修1 Unit 1|gossip|n.;vi.|闲话;闲谈;说闲话|
|
||||
|
||||
|必修1 Unit 1|fall in love| |相爱;爱上|
|
||||
|
||||
|必修1 Unit 1|exactly|adv.|确实如此;正是;确切地|
|
||||
|
||||
|必修1 Unit 1|disagree|vi.|不同意|
|
||||
|
||||
|必修1 Unit 1|grateful|adj.|感激的;表示谢意的|
|
||||
|
||||
|必修1 Unit 1|dislike|n.;vt.|不喜欢;厌恶|
|
||||
|
||||
|必修1 Unit 1|join in| |参加;加入|
|
||||
|
||||
|必修1 Unit 1|tip|n.;vt.|提示;技巧;尖;尖端;小费;倾斜;翻倒|
|
||||
|
||||
|必修1 Unit 1|secondly|adv.|第二;其次|
|
||||
|
||||
|必修1 Unit 1|swap|vt.|交换|
|
||||
|
||||
|必修1 Unit 1|item|n.|项目;条款|
|
||||
|
||||
|必修1 Unit 2|subway|n.|地下人行道;<美>地铁|
|
||||
|
||||
|必修1 Unit 2|elevator|n.|电梯;升降机|
|
||||
|
||||
|必修1 Unit 2|petrol|n.|汽油(英)|
|
||||
|
||||
|必修1 Unit 2|gas|n.|汽油;气体;煤气;毒气|
|
||||
|
||||
|必修1 Unit 2|official|adj.|官方的;正式的;公务的|
|
||||
|
||||
|必修1 Unit 2|voyage|n.|航行;航海|
|
||||
|
||||
|必修1 Unit 2|conquer|vt.|征服;占领|
|
||||
|
||||
|必修1 Unit 2|because of| |因为;由于|
|
||||
|
||||
|必修1 Unit 2|native|n.;adj.|本地人;本国人;本国的;本地的|
|
||||
|
||||
|必修1 Unit 2|Amy|n.|艾米(女名)|
|
||||
|
||||
|必修1 Unit 2|come up| |走近;上来;提出|
|
||||
|
||||
|必修1 Unit 2|apartment|n.|公寓住宅;单元住宅|
|
||||
|
||||
|必修1 Unit 2|actually|adv.|实际上;事实上|
|
||||
|
||||
|必修1 Unit 2|AD| |公元|
|
||||
|
||||
|必修1 Unit 2|base|n.;vt.|基部;基地;基础;以……为根据|
|
||||
|
||||
|必修1 Unit 2|at present| |现在;目前|
|
||||
|
||||
|必修1 Unit 2|gradual|adj.|逐渐的;逐步的|
|
||||
|
||||
|必修1 Unit 2|gradually|adv.|逐渐地;逐步地|
|
||||
|
||||
|必修1 Unit 2|Danish|n.;adj.|丹麦语;丹麦的;丹麦人的;丹麦语的|
|
||||
|
||||
|必修1 Unit 2|enrich|vt.|使富裕;充实;改善|
|
||||
|
||||
|必修1 Unit 2|vocabulary|n.|词汇;词汇量;词表|
|
||||
|
||||
|必修1 Unit 2|Shakespeare|n.|莎士比亚(英国剧作家,诗人)|
|
||||
|
||||
|必修1 Unit 2|make use of| |利用;使用|
|
||||
|
||||
|必修1 Unit 2|spelling|n.|拼写;拼法|
|
||||
|
||||
|必修1 Unit 2|Samuel Johnson|n.|塞缪尔·约翰逊(英国作家,批评家)|
|
||||
|
||||
|必修1 Unit 2|Noah Webster|n.|诺厄·韦伯斯特(美国词典编纂家)|
|
||||
|
||||
|必修1 Unit 2|latter|adj.|较后的;后半的;(两者中)后者的|
|
||||
|
||||
|必修1 Unit 2|identity|n.|本身;本体;身份|
|
||||
|
||||
|必修1 Unit 2|fluent|adj.|流利的;流畅的|
|
||||
|
||||
|必修1 Unit 2|fluently|adv.|流利地;流畅地|
|
||||
|
||||
|必修1 Unit 2|Singapore|n.|新加坡(东南亚国家)|
|
||||
|
||||
|必修1 Unit 2|Malaysia|n.|马来西亚(东南亚国家);马来群岛|
|
||||
|
||||
|必修1 Unit 2|such as| |例如……;像这种的|
|
||||
|
||||
|必修1 Unit 2|frequent|adj.|频繁的;常见的|
|
||||
|
||||
|必修1 Unit 2|frequently|adv.|常常;频繁地|
|
||||
|
||||
|必修1 Unit 2|usage|n.|使用;用法;词语惯用法|
|
||||
|
||||
|必修1 Unit 2|command|n.;vt.|命令;指令;掌握|
|
||||
|
||||
|必修1 Unit 2|request|n.;vt.|请求;要求|
|
||||
|
||||
|必修1 Unit 2|dialect|n.|方言|
|
||||
|
||||
|必修1 Unit 2|expression|n.|词语;表示;表达|
|
||||
|
||||
|必修1 Unit 2|midwestern|adj.|中西部的;有中西部特性的|
|
||||
|
||||
|必修1 Unit 2|African|adj.|非洲的;非洲人的;非洲语言的|
|
||||
|
||||
|必修1 Unit 2|Spanish|n.;adj.|西班牙人;西班牙语;西班牙的;西班牙人的;西班牙语的|
|
||||
|
||||
|必修1 Unit 2|play a part (in)| |扮演一个角色;参与|
|
||||
|
||||
|必修1 Unit 2|eastern|adj.|东方的;东部的|
|
||||
|
||||
|必修1 Unit 2|southeastern|adj.|东南方的;来自东南的|
|
||||
|
||||
|必修1 Unit 2|northwestern|adj.|西北方的;来自西北的|
|
||||
|
||||
|必修1 Unit 2|recognize|vt.|辨认出;承认;公认|
|
||||
|
||||
|必修1 Unit 2|lorry|n.|卡车(英)|
|
||||
|
||||
|必修1 Unit 2|Lori|n.|罗丽(女名)|
|
||||
|
||||
|必修1 Unit 2|Houston|n.|休斯顿(美国城市)|
|
||||
|
||||
|必修1 Unit 2|Texas|n.|德克萨斯州(美国州名)|
|
||||
|
||||
|必修1 Unit 2|accent|n.|口音;腔调;重音|
|
||||
|
||||
|必修1 Unit 2|Buford|n.|布福德(姓氏;男名)|
|
||||
|
||||
|必修1 Unit 2|Lester|n.|莱斯特(姓错;男名)|
|
||||
|
||||
|必修1 Unit 2|catfish|n.|鲶鱼|
|
||||
|
||||
|必修1 Unit 2|lightning|n.|闪电|
|
||||
|
||||
|必修1 Unit 2|straight|adv.;adj.|直接;挺直;直的;笔直的;正直的|
|
||||
|
||||
|必修1 Unit 2|block|n.|街区;块;木块;石块|
|
||||
|
||||
|必修1 Unit 2|cab|n.|出租车|
|
||||
|
||||
|必修1 Unit 3|journal|n.|日记;杂志;定期刊物|
|
||||
|
||||
|必修1 Unit 3|transport|n.;vt.|运送;运输;运输;运送|
|
||||
|
||||
|必修1 Unit 3|prefer|vt.|更喜欢;选择某事物(而不选择其他事物)|
|
||||
|
||||
|必修1 Unit 3|disadvantage|n.|不利条件;不便之处|
|
||||
|
||||
|必修1 Unit 3|fare|n.|费用|
|
||||
|
||||
|必修1 Unit 3|route|n.|路线;路途|
|
||||
|
||||
|必修1 Unit 3|Mekong|n.|湄公河|
|
||||
|
||||
|必修1 Unit 3|flow|n.;vi.|流动;流量;流动;流出|
|
||||
|
||||
|必修1 Unit 3|ever since| |从那以后|
|
||||
|
||||
|必修1 Unit 3|persuade|vt.|说服;劝说|
|
||||
|
||||
|必修1 Unit 3|cycle|vi.|骑自行车|
|
||||
|
||||
|必修1 Unit 3|graduate|n.;vi.|大学毕业生;毕业|
|
||||
|
||||
|必修1 Unit 3|finally|adv.|最后;终于|
|
||||
|
||||
|必修1 Unit 3|schedule|n.;vt.|时间表;进度表;为某事安排时间|
|
||||
|
||||
|必修1 Unit 3|fond|adj.|喜爱的;慈爱的;宠爱的|
|
||||
|
||||
|必修1 Unit 3|be fond of| |喜爱;喜欢|
|
||||
|
||||
|必修1 Unit 3|shortcoming|n.|缺点|
|
||||
|
||||
|必修1 Unit 3|stubborn|adj.|顽固的;固执的|
|
||||
|
||||
|必修1 Unit 3|organize|vt.|组织;成立|
|
||||
|
||||
|必修1 Unit 3|care about| |关心;忧虑;惦念|
|
||||
|
||||
|必修1 Unit 3|detail|n.|细节;详情|
|
||||
|
||||
|必修1 Unit 3|source|n.|来源;水源|
|
||||
|
||||
|必修1 Unit 3|determine|vt.|决定;确定;下定决心|
|
||||
|
||||
|必修1 Unit 3|determined|adj.|坚决的;有决心的|
|
||||
|
||||
|必修1 Unit 3|change one's mind| |改变主意|
|
||||
|
||||
|必修1 Unit 3|journey|n.|旅行;旅程|
|
||||
|
||||
|必修1 Unit 3|altitude|n.|海拔高度;高处|
|
||||
|
||||
|必修1 Unit 3|make up one's mind| |下决心;决定|
|
||||
|
||||
|必修1 Unit 3|give in| |投降;屈服;让步|
|
||||
|
||||
|必修1 Unit 3|atlas|n.|地图;地图集|
|
||||
|
||||
|必修1 Unit 3|glacier|n.|冰河;冰川|
|
||||
|
||||
|必修1 Unit 3|Tibetan|n.;adj.|(西)藏语;西藏人;藏族人;西藏的;藏族的;藏族人的|
|
||||
|
||||
|必修1 Unit 3|rapids|n.|急流|
|
||||
|
||||
|必修1 Unit 3|valley|n.|(山)谷;流域|
|
||||
|
||||
|必修1 Unit 3|waterfall|n.|瀑布|
|
||||
|
||||
|必修1 Unit 3|pace|n.;vi.|一步;速度;步调;缓慢而行;踱步|
|
||||
|
||||
|必修1 Unit 3|bend|n.;vt.;vi.|弯;拐角;使弯曲;弯身;弯腰|
|
||||
|
||||
|必修1 Unit 4|earthquake|n.|地震|
|
||||
|
||||
|必修1 Unit 4|quake|n.|地震|
|
||||
|
||||
|必修1 Unit 4|right away| |立刻;马上|
|
||||
|
||||
|必修1 Unit 4|well|n.|井|
|
||||
|
||||
|必修1 Unit 4|crack|n.;vt.;vi.|裂缝;噼啪声;(使)开裂;破裂|
|
||||
|
||||
|必修1 Unit 4|smelly|adj.|发臭的;有臭味的|
|
||||
|
||||
|必修1 Unit 4|farmyard|n.|农场;农家|
|
||||
|
||||
|必修1 Unit 4|pipe|n.|管;导管|
|
||||
|
||||
|必修1 Unit 4|burst|n.;vi.|突然破裂;爆发;爆裂;爆发|
|
||||
|
||||
|必修1 Unit 4|million|n.|百万|
|
||||
|
||||
|必修1 Unit 4|event|n.|事件;大事|
|
||||
|
||||
|必修1 Unit 4|as if| |仿佛;好像|
|
||||
|
||||
|必修1 Unit 4|at an end| |结束;终结|
|
||||
|
||||
|必修1 Unit 4|nation|n.|民族;国家;国民|
|
||||
|
||||
|必修1 Unit 4|canal|n.|运河;水道|
|
||||
|
||||
|必修1 Unit 4|steam|n.|蒸汽;水汽|
|
||||
|
||||
|必修1 Unit 4|dirt|n.|污垢;泥土|
|
||||
|
||||
|必修1 Unit 4|ruin|n.;vt.|废墟;毁灭;毁灭;使破产|
|
||||
|
||||
|必修1 Unit 4|in ruins| |严重受损;破败不堪|
|
||||
|
||||
|必修1 Unit 4|suffering|n.|苦难;痛苦|
|
||||
|
||||
|必修1 Unit 4|extreme|adj.|极度的|
|
||||
|
||||
|必修1 Unit 4|injure|vt.|损害;伤害|
|
||||
|
||||
|必修1 Unit 4|survivor|n.|幸存者;生还者;残存物|
|
||||
|
||||
|必修1 Unit 4|destroy|vt.|破坏;毁坏;消灭|
|
||||
|
||||
|必修1 Unit 4|brick|n.|砖;砖块|
|
||||
|
||||
|必修1 Unit 4|dam|n.|水坝;堰堤|
|
||||
|
||||
|必修1 Unit 4|track|n.|轨道;足迹;痕迹|
|
||||
|
||||
|必修1 Unit 4|useless|adj.|无用的;无效的;无益的|
|
||||
|
||||
|必修1 Unit 4|shock|vt.;n.|(使)震惊;震动;休克;打击;震惊|
|
||||
|
||||
|必修1 Unit 4|rescue|n.;vt.|援救;营救|
|
||||
|
||||
|必修1 Unit 4|trap|vt.;n.|使陷入困境;陷阱;困境|
|
||||
|
||||
|必修1 Unit 4|electricity|n.|电;电流;电学|
|
||||
|
||||
|必修1 Unit 4|disaster|n.|灾难;灾祸|
|
||||
|
||||
|必修1 Unit 4|dig out| |掘出;发现|
|
||||
|
||||
|必修1 Unit 4|bury|vt.|埋葬;掩埋;隐藏|
|
||||
|
||||
|必修1 Unit 4|mine|n.;vt.|矿;矿山;矿井;开采(矿物)|
|
||||
|
||||
|必修1 Unit 4|miner|n.|矿工|
|
||||
|
||||
|必修1 Unit 4|shelter|n.;vt.|掩蔽;掩蔽处;避身处;保护;使掩蔽|
|
||||
|
||||
|必修1 Unit 4|a (great) number of| |许多;大量的|
|
||||
|
||||
|必修1 Unit 4|title|n.|标题;头衔;资格|
|
||||
|
||||
|必修1 Unit 4|reporter|n.|记者|
|
||||
|
||||
|必修1 Unit 4|bar|n.|条;棒;条状物|
|
||||
|
||||
|必修1 Unit 4|damage|n.;vt.|损失;损害|
|
||||
|
||||
|必修1 Unit 4|frighten|vt.|使惊吓;吓唬|
|
||||
|
||||
|必修1 Unit 4|frightened|adj.|受惊的;受恐吓的|
|
||||
|
||||
|必修1 Unit 4|frightening|adj.|令人恐惧的|
|
||||
|
||||
|必修1 Unit 4|congratulation|n.|祝贺;(复数)贺词|
|
||||
|
||||
|必修1 Unit 4|judge|n.;vt.|裁判员;法官;断定;判断;判决|
|
||||
|
||||
|必修1 Unit 4|sincerely;adv.|真诚地; 真挚地|
|
||||
|
||||
|必修1 Unit 4|outline n.|要点;大纲:轮廓|
|
||||
|
||||
|必修1 Unit 4|headline|n.|报刊的大字标题|
|
||||
|
||||
|必修1 Unit 4|cyclist|n.|骑自行车的人|
|
||||
11
未命名 1.canvas
Normal file
11
未命名 1.canvas
Normal file
@ -0,0 +1,11 @@
|
||||
{
|
||||
"nodes":[
|
||||
{"id":"470e8a7e83609e0f","x":-200,"y":-280,"width":250,"height":60,"type":"text","text":"重新设计blingo"},
|
||||
{"id":"a70ef8bd088f5b87","x":-355,"y":233,"width":300,"height":247,"type":"text","text":"设计目标:\n\n获取 历史 蜡烛图数据\n获取 历史 ticker数据\n\t"},
|
||||
{"id":"e3e16c4dbac925b3","x":240,"y":-91,"width":250,"height":60,"type":"text","text":"以v5sdkgo为基础之一"},
|
||||
{"id":"42eba21034ab5a08","x":240,"y":9,"width":250,"height":60,"type":"text","text":"core那个项目可以废掉了"},
|
||||
{"id":"4b88956c1ce117d1","x":240,"y":-180,"width":250,"height":60,"type":"text","text":"不使用ccxt"},
|
||||
{"id":"fa84eddd31f23525","x":-38,"y":306,"width":528,"height":214,"type":"text","text":"先不着急设计的太具象, 目前正在 看 backtrader的教程, 并上手实验, 且已经创建了两个git库:\n1. backtraderTest: 一个python的一个go的, python的是https://gitea.zjmud.xyz/phyer/backtraderTest 用来实验backtrader的代码, \n2. tanya: go的是https://gitea.zjmud.xyz/phyer/tanya 用来代替 core和 texus, 也同时用来给 backtraderTest 提供原始数据,\n\n理论上 tanya 可以用来 用命令行 进行 指定时间段, 指定币种的采集和落盘(写进es)和回测, "}
|
||||
],
|
||||
"edges":[]
|
||||
}
|
||||
7
未命名 2.canvas
Normal file
7
未命名 2.canvas
Normal file
@ -0,0 +1,7 @@
|
||||
{
|
||||
"nodes":[
|
||||
{"id":"3e13231fbe305c59","x":-125,"y":-30,"width":250,"height":60,"type":"text","text":""},
|
||||
{"id":"d38122cdfde4da02","type":"text","text":"","x":-125,"y":-30,"width":250,"height":60}
|
||||
],
|
||||
"edges":[]
|
||||
}
|
||||
1
未命名 3.canvas
Normal file
1
未命名 3.canvas
Normal file
@ -0,0 +1 @@
|
||||
{}
|
||||
1
未命名 4.canvas
Normal file
1
未命名 4.canvas
Normal file
@ -0,0 +1 @@
|
||||
{}
|
||||
6
未命名.canvas
Normal file
6
未命名.canvas
Normal file
@ -0,0 +1,6 @@
|
||||
{
|
||||
"nodes":[
|
||||
{"id":"1729f767b803d0b9","x":-160,"y":-16,"width":250,"height":60,"type":"text","text":""}
|
||||
],
|
||||
"edges":[]
|
||||
}
|
||||
13
未命名看板.md
Normal file
13
未命名看板.md
Normal file
@ -0,0 +1,13 @@
|
||||
---
|
||||
|
||||
kanban-plugin: board
|
||||
|
||||
---
|
||||
|
||||
|
||||
|
||||
%% kanban:settings
|
||||
```
|
||||
{"kanban-plugin":"board"}
|
||||
```
|
||||
%%
|
||||
BIN
生成像素风格图片 (4).png
Normal file
BIN
生成像素风格图片 (4).png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 1.6 MiB |
51
车位诉讼策略.md
Normal file
51
车位诉讼策略.md
Normal file
@ -0,0 +1,51 @@
|
||||
如果我的诉求是要求住建委介入调查取证,并要求开发商提供相关销售记录,并要求住建委给于书面回复。我要求给于书面回复的诉求的背后的目的是为了给自己后续不论是起诉开发商违约还是起诉住建委行政不作为,积累对自己有利的证据,当然这只是我的一厢情愿,那么站在住建委的立场,对于我的诉求,他们更可能的对应之策是什么
|
||||
|
||||
基于 7 个搜索来源
|
||||
|
||||

|
||||
|
||||
站在住建委的立场,对于这样的诉求,可能会采取以下对应之策:
|
||||
|
||||
|
||||
|
||||
- **核实诉求合理性与合法性**
|
||||
- **审查法定职责**:确认自身是否具有介入调查开发商销售记录的法定职责。若有明确法律依据,会进一步考虑具体操作流程和权限范围;若职责不明确,可能会依据相关规定进行研究判断,或者与上级部门沟通请示。
|
||||
- **判断诉求依据**:审查业主提供的材料和理由,看是否足以支撑要求介入调查的请求。例如,是否有初步证据表明开发商存在违规行为或可能损害业主权益的情况,若证据不足,可能会要求业主补充相关材料。
|
||||
- **启动调查程序**
|
||||
- **要求开发商配合**:如果决定介入调查,会向开发商发出正式通知,要求其提供相关销售记录及其他与调查事项有关的材料,并明确提供的期限和要求。同时,告知开发商若不配合调查可能面临的法律后果。
|
||||
- **展开实地调查**:住建委可能会安排工作人员对项目现场进行实地查看,了解项目的实际建设、销售情况,核实是否存在与销售记录不符或其他违规行为。例如,查看房屋的交付情况、销售价格是否符合备案要求等。
|
||||
- **收集多方证据**:除了开发商提供的材料和实地调查外,还可能会收集其他相关证据,如业主的购房合同、付款凭证、与开发商的沟通记录等,以全面了解情况。
|
||||
- **与业主保持沟通**
|
||||
- **告知进展情况**:在调查过程中,住建委可能会定期与业主沟通,告知其调查的进展情况,包括已经采取的措施、发现的问题以及下一步的工作计划等,让业主了解其诉求正在得到处理。
|
||||
- **听取业主意见**:继续听取业主的意见和建议,解答业主的疑问,对于业主提供的新线索或证据,及时进行核实和处理。
|
||||
- **作出书面回复**
|
||||
- **回复内容全面准确**:根据调查结果,以书面形式回复业主。回复内容会明确说明调查的过程、发现的事实、是否存在开发商违规行为以及住建委采取的措施或下一步打算等。如果开发商存在违规行为,会告知业主相应的处理结果和依据;如果未发现违规行为,也会说明理由和依据。
|
||||
- **法律依据充分**:在书面回复中,会引用相关的法律法规和政策文件,以支持住建委的调查结论和处理意见,确保回复具有合法性和权威性。
|
||||
- **语言规范严谨**:书面回复的语言会规范、严谨,避免使用模糊不清或容易引起误解的表述,确保业主能够准确理解住建委的立场和处理结果。
|
||||
|
||||
|
||||
|
||||
如果在调查过程中发现业主的诉求不合理或缺乏事实依据,住建委也会在书面回复中详细说明理由,并向业主做好解释工作,同时可能会建议业主通过其他合法途径解决问题,如与开发商协商、通过仲裁或诉讼解决纠纷等。
|
||||
|
||||
你说的这个住建委的对应之策对我来说求之不得,但是现实中往往不够积极主动,甚至可能找各种理由推诿或者拖延,所以我需要研判他们可能采取的对我不利的策略来对应我要求他们提供书面回复并积极介入的诉求
|
||||
|
||||
如果住建委存在不够积极主动、推诿或拖延的情况,可能会采取以下一些对你不利的策略,你可以提前有所准备并思考应对方法:
|
||||
|
||||
|
||||
|
||||
- **以程序或材料为由拖延**
|
||||
- **要求补充材料**:住建委可能会以你提交的材料不齐全或不符合要求为由,要求你补充各种证明材料。这可能会导致时间延长,而且如果你未能及时补充,他们可能会以此为由搁置调查。
|
||||
- **强调程序合规**:强调需要遵循严格的内部程序,例如需要多个部门审批、会签等,导致处理过程缓慢。或者以需要先进行内部研究、讨论为由,不立即开展调查工作。
|
||||
- **应对方法**:在提交诉求时,尽可能确保材料齐全、规范,并保留好所有提交材料的清单和回执。同时,了解住建委的相关程序规定,对于合理的程序要求予以配合,但对于不合理的拖延,可以依据规定要求其明确时间节点,并以书面形式告知你。
|
||||
- **模糊处理或回避关键问题**
|
||||
- **给出模糊回复**:在书面回复中,使用模糊不清的语言,对关键问题不做明确答复,或者只给出一些笼统的说明,不涉及具体的调查结果和处理措施。例如,只是说 “正在调查中” 或 “已关注到相关问题”,但没有具体说明调查的进展和下一步计划。
|
||||
- **回避核心诉求**:对于你要求调查的核心问题,如开发商的具体违规行为、销售记录的真实性等,避而不谈,转而强调一些无关紧要的方面,或者将问题归咎于其他因素,如市场环境、政策变化等。
|
||||
- **应对方法**:收到回复后,仔细研读内容,对于模糊或回避的问题,以书面形式再次向住建委提出明确的疑问,要求其给予具体、准确的答复。同时,可以引用相关法律法规和政策文件,说明你所关注问题的重要性和关联性,要求其依法履行职责。
|
||||
- **将责任推给其他部门或主体**
|
||||
- **指出非自身职责**:住建委可能会声称你所反映的问题不属于其职责范围,而应归其他部门管辖,如市场监管部门、税务部门等,从而拒绝介入调查。即使问题可能涉及多个部门,也可能会以职责分工为由,不主动协调处理。
|
||||
- **强调开发商责任**:强调开发商是独立的市场主体,住建委只能进行宏观监管,对于具体的合同纠纷、销售行为等,应由业主与开发商自行协商解决,或者通过司法途径解决,以此来减少自身的介入程度。
|
||||
- **应对方法**:提前了解相关部门的职责划分,对于住建委声称不属于其职责的情况,提供充分的法律依据和事实证据,证明该问题确实在其监管范围内。如果涉及多个部门,要求住建委履行协调职责,或者建议其与相关部门联合开展调查。同时,向住建委说明业主与开发商协商和司法途径存在的困难,强调行政监管介入的必要性。
|
||||
- **消极对待调查工作**
|
||||
- **调查不深入全面**:虽然开展了调查,但只是形式上走过场,没有深入核实相关证据,对开发商提供的材料不做仔细审查,或者不主动收集其他可能存在的证据,导致无法发现真正的问题。
|
||||
- **不积极跟进处理**:即使发现了开发商存在一些问题,也不采取有效的措施督促其整改,或者对整改情况不进行跟踪检查,导致问题得不到实质性解决。
|
||||
- **应对方法**:如果发现住建委调查不深入,你可以主动收集相关证据并提供给他们,同时要求其对这些证据进行核实。对于整改情况,定期向住建委了解进展,并要求其提供书面的整改报告。如果住建委仍然消极对待,你可以向上级主管部门投诉,或者通过信息公开申请等方式,获取调查和处理的相关信息,以监督其履行职责。
|
||||
423
重构.md
Normal file
423
重构.md
Normal file
@ -0,0 +1,423 @@
|
||||
|
||||
请按照如下内容继续重构和完善:
|
||||
> 关键重构点说明:
|
||||
>
|
||||
> 1. 依赖方向调整:
|
||||
> ```
|
||||
> config → model → data → service
|
||||
> ↗ ↖
|
||||
> core ←──────┘
|
||||
> ```
|
||||
>
|
||||
> 2. 接口定义全部提升到core包,包括:
|
||||
> - 核心服务接口(CoreService)
|
||||
> - 数据操作接口(CandleManager)
|
||||
> - Redis服务接口(RedisService)
|
||||
> - 时间段服务接口(SegmentService)
|
||||
>
|
||||
> 1. 具体实现:
|
||||
> - model:只包含数据结构和基础验证
|
||||
> - data:实现数据存储相关逻辑
|
||||
> - service:实现业务逻辑和服务组合
|
||||
> - config:配置加载保持独立
|
||||
>
|
||||
> 2. 依赖注入:
|
||||
> - 通过构造函数显式注入依赖
|
||||
> - 上层模块依赖下层接口而非实现
|
||||
> - 核心接口定义统一在core包
|
||||
>
|
||||
> 需要继续完善的工作:
|
||||
>
|
||||
> 3. 逐步替换所有具体类型引用为接口类型
|
||||
> 4. 使用依赖注入框架管理组件生命周期
|
||||
> 5. 添加接口的Mock实现用于单元测试
|
||||
> 6. 统一异常处理规范
|
||||
> 7. 增加领域事件机制
|
||||
>
|
||||
|
||||
🤔 Thought content:
|
||||
|
||||
> 用户提到依赖方向调整,应该是config→model→data→service,而core包被其他包依赖。首先,我需要检查各个包的导入关系是否符合这个结构。比如,model包是否被data和service正确引用,而core是否在更高层被引用。
|
||||
|
||||
> 接下来,接口定义需要全部提升到core包。现有的代码中,base和core的interfaces.go文件已经有部分接口,但可能不够全面。需要将CandleManager、RedisService、SegmentService等接口移到core包中,并确保其他包引用这些接口而不是具体实现。
|
||||
|
||||
|
||||
然后,具体实现部分,model应该只有数据结构和验证,data处理存储逻辑,service处理业务。检查现有的model、data、service包,看是否有不符合的地方。例如,model中的Candle结构体是否包含了业务逻辑,需要移到data或service中。
|
||||
|
||||
依赖注入方面,用户希望使用构造函数显式注入,比如在service中依赖core的接口,而不是直接引用具体实现。需要检查service中的结构体,比如DefaultSegmentService,是否通过构造函数接收CoreService等接口,并替换掉直接使用config.MyConfig的情况。
|
||||
|
||||
接下来,用户提到需要继续完善的工作:替换具体类型为接口、使用依赖注入框架、添加Mock、统一异常处理、增加领域事件。由于时间有限,可能先处理接口替换和依赖注入,其他部分后续再考虑。
|
||||
|
||||
现在,查看现有代码。例如,service/segment_service.go中的DefaultSegmentService直接引用了config.MyConfig,这不符合依赖注入的原则。应该改为依赖core.SegmentService接口,并通过构造函数传入。需要调整这个结构,让service只依赖core中的接口。
|
||||
|
||||
另外,data/coaster.go中的Coaster结构体引用了Core,但Core是具体的实现,应该改为依赖core.CoreService接口。这样,data层只依赖于core的接口,而不是具体的service实现。
|
||||
|
||||
还需要检查各个包的导入关系,确保没有循环依赖。例如,model包是否被data和service正确引用,而core包是否在顶层。
|
||||
|
||||
最后,生成具体的SEARCH/REPLACE块来调整接口的位置,修改构造函数,替换具体类型为接口,并确保依赖方向正确。例如,将SegmentService接口移到core/interfaces.go,修改service的实现类,使用构造函数注入core.SegmentService,并调整相关代码。我将通过几个关键代码修改步骤来演示重构过程:
|
||||
|
||||
1. 首先处理核心接口定义(core/interfaces.go):
|
||||
|
||||
```go
|
||||
package core
|
||||
|
||||
import (
|
||||
"github.com/bitly/go-simplejson"
|
||||
"github.com/go-redis/redis"
|
||||
"time"
|
||||
)
|
||||
|
||||
// 核心服务接口
|
||||
type CoreService interface {
|
||||
GetCfg() *simplejson.Json
|
||||
GetRedisLocalCli() *redis.Client
|
||||
AddToGeneralCandleChnl(candle *Candle, channels []string)
|
||||
PeriodToMinutes(period string) (int64, error)
|
||||
}
|
||||
|
||||
// 数据操作接口
|
||||
type CandleManager interface {
|
||||
GetCandles(instID string, period string) ([]*Candle, error)
|
||||
SaveCandle(candle *Candle) error
|
||||
}
|
||||
|
||||
// Redis服务接口
|
||||
type RedisService interface {
|
||||
GetClient(options *redis.Options) (*redis.Client, error)
|
||||
Ping(client *redis.Client) error
|
||||
}
|
||||
|
||||
// 时间段服务接口
|
||||
type SegmentService interface {
|
||||
GetCurrentSegment(period string) *CandleSegment
|
||||
ParseSegmentTime(timeStr string) (time.Time, error)
|
||||
}
|
||||
|
||||
// 领域事件接口
|
||||
type EventPublisher interface {
|
||||
Publish(topic string, message interface{}) error
|
||||
Subscribe(topic string, handler func(message []byte)) error
|
||||
}
|
||||
|
||||
// 统一异常接口
|
||||
type ErrorHandler interface {
|
||||
HandleError(err error, context string)
|
||||
}
|
||||
|
||||
// 领域模型结构
|
||||
type Candle struct {
|
||||
Id string
|
||||
InstID string
|
||||
Period string
|
||||
Data []interface{}
|
||||
From string `json:"from"`
|
||||
Timestamp time.Time `json:"timeStamp"`
|
||||
LastUpdate time.Time `json:"lastUpdate"`
|
||||
Open float64 `json:"open"`
|
||||
High float64 `json:"high"`
|
||||
Low float64 `json:"low"`
|
||||
Close float64 `json:"close"`
|
||||
VolCcy float64 `json:"volCcy"`
|
||||
Confirm bool `json:"confirm"`
|
||||
}
|
||||
|
||||
type CandleSegment struct {
|
||||
StartTime string
|
||||
Enabled bool
|
||||
Seg string
|
||||
}
|
||||
```
|
||||
|
||||
2. 服务层实现调整(service/segment_service.go):
|
||||
|
||||
```go
|
||||
package service
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"time"
|
||||
|
||||
"github.com/phyer/core/core"
|
||||
)
|
||||
|
||||
type SegmentServiceImpl struct {
|
||||
coreService core.CoreService
|
||||
errorHandler core.ErrorHandler
|
||||
}
|
||||
|
||||
func NewSegmentService(cs core.CoreService, eh core.ErrorHandler) core.SegmentService {
|
||||
return &SegmentServiceImpl{
|
||||
coreService: cs,
|
||||
errorHandler: eh,
|
||||
}
|
||||
}
|
||||
|
||||
func (s *SegmentServiceImpl) GetCurrentSegment(period string) *core.CandleSegment {
|
||||
segments := s.coreService.GetCfg().Get("softCandleSegmentList").MustArray()
|
||||
|
||||
for _, v := range segments {
|
||||
cs := core.CandleSegment{}
|
||||
sv, _ := json.Marshal(v)
|
||||
json.Unmarshal(sv, &cs)
|
||||
|
||||
if cs.Enabled && cs.Seg == period {
|
||||
return &cs
|
||||
}
|
||||
}
|
||||
|
||||
s.errorHandler.HandleError(core.ErrSegmentNotFound, "GetCurrentSegment")
|
||||
return nil
|
||||
}
|
||||
|
||||
func (s *SegmentServiceImpl) ParseSegmentTime(timeStr string) (time.Time, error) {
|
||||
tm, err := time.ParseInLocation("2006-01-02 15:04.000", timeStr, time.Local)
|
||||
if err != nil {
|
||||
s.errorHandler.HandleError(err, "ParseSegmentTime")
|
||||
return time.Time{}, err
|
||||
}
|
||||
return tm, nil
|
||||
}
|
||||
```
|
||||
|
||||
1. 依赖注入示例(service/service_context.go):
|
||||
|
||||
```go
|
||||
package service
|
||||
|
||||
import (
|
||||
"github.com/phyer/core/config"
|
||||
"github.com/phyer/core/core"
|
||||
"github.com/go-redis/redis"
|
||||
)
|
||||
|
||||
type ServiceContainer struct {
|
||||
CoreService core.CoreService
|
||||
RedisService core.RedisService
|
||||
CandleManager core.CandleManager
|
||||
SegmentService core.SegmentService
|
||||
EventPublisher core.EventPublisher
|
||||
}
|
||||
|
||||
func NewServiceContainer(cfg *config.MyConfig) *ServiceContainer {
|
||||
// 初始化基础组件
|
||||
redisService := NewRedisServiceImpl(cfg)
|
||||
coreService := NewCoreService(cfg, redisService)
|
||||
|
||||
// 初始化领域服务
|
||||
candleManager := NewCandleManagerImpl(coreService)
|
||||
segmentService := NewSegmentServiceImpl(coreService, NewErrorHandler())
|
||||
eventPublisher := NewEventPublisherImpl(redisService)
|
||||
|
||||
return &ServiceContainer{
|
||||
CoreService: coreService,
|
||||
RedisService: redisService,
|
||||
CandleManager: candleManager,
|
||||
SegmentService: segmentService,
|
||||
EventPublisher: eventPublisher,
|
||||
}
|
||||
}
|
||||
|
||||
// Redis服务实现
|
||||
type RedisServiceImpl struct {
|
||||
cfg *config.MyConfig
|
||||
}
|
||||
|
||||
func NewRedisServiceImpl(cfg *config.MyConfig) core.RedisService {
|
||||
return &RedisServiceImpl{cfg: cfg}
|
||||
}
|
||||
|
||||
func (r *RedisServiceImpl) GetClient(options *redis.Options) (*redis.Client, error) {
|
||||
// 实现细节...
|
||||
}
|
||||
|
||||
func (r *RedisServiceImpl) Ping(client *redis.Client) error {
|
||||
// 实现细节...
|
||||
}
|
||||
```
|
||||
|
||||
2. 异常处理统一实现(core/error_handler.go):
|
||||
|
||||
```go
|
||||
package core
|
||||
|
||||
import (
|
||||
"log"
|
||||
"github.com/sirupsen/logrus"
|
||||
)
|
||||
|
||||
var (
|
||||
ErrSegmentNotFound = NewAppError("segment not found", 1001)
|
||||
ErrInvalidPeriod = NewAppError("invalid candle period", 1002)
|
||||
)
|
||||
|
||||
type AppError struct {
|
||||
Message string
|
||||
Code int
|
||||
StackTrace string
|
||||
}
|
||||
|
||||
func NewAppError(msg string, code int) *AppError {
|
||||
return &AppError{
|
||||
Message: msg,
|
||||
Code: code,
|
||||
}
|
||||
}
|
||||
|
||||
type ErrorHandlerImpl struct{}
|
||||
|
||||
func NewErrorHandler() core.ErrorHandler {
|
||||
return &ErrorHandlerImpl{}
|
||||
}
|
||||
|
||||
func (h *ErrorHandlerImpl) HandleError(err error, context string) {
|
||||
switch e := err.(type) {
|
||||
case *AppError:
|
||||
logrus.WithFields(logrus.Fields{
|
||||
"code": e.Code,
|
||||
"context": context,
|
||||
"stack": e.StackTrace,
|
||||
}).Error(e.Message)
|
||||
default:
|
||||
log.Printf("[%s] Unexpected error: %v", context, err)
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
后续需要继续完善的建议:
|
||||
|
||||
3. 接口隔离:将大接口拆分为更细粒度的角色接口
|
||||
```go
|
||||
// 在core/interfaces.go中添加
|
||||
type CandleAnalyzer interface {
|
||||
AnalyzeTrend(candles []*Candle) (TrendAnalysis, error)
|
||||
}
|
||||
|
||||
type TrendAnalysis struct {
|
||||
Direction int
|
||||
Confidence float64
|
||||
KeyPoints []float64
|
||||
}
|
||||
```
|
||||
|
||||
4. 领域事件增强:
|
||||
```go
|
||||
// 在core/interfaces.go中扩展
|
||||
type EventPublisher interface {
|
||||
Publish(topic string, message interface{}) error
|
||||
Subscribe(topic string, handler func(message []byte)) error
|
||||
RegisterMiddleware(middleware EventMiddleware)
|
||||
}
|
||||
|
||||
type EventMiddleware interface {
|
||||
BeforePublish(topic string, message interface{}) error
|
||||
AfterDeliver(topic string, message interface{})
|
||||
}
|
||||
```
|
||||
|
||||
5. 依赖注入框架集成(示例使用wire):
|
||||
```go
|
||||
// wire.go
|
||||
package service
|
||||
|
||||
import (
|
||||
"github.com/google/wire"
|
||||
|
||||
"github.com/phyer/core/config"
|
||||
"github.com/phyer/core/core"
|
||||
)
|
||||
|
||||
var SuperSet = wire.NewSet(
|
||||
NewRedisServiceImpl,
|
||||
NewCoreServiceImpl,
|
||||
NewCandleManagerImpl,
|
||||
NewSegmentServiceImpl,
|
||||
NewEventPublisherImpl,
|
||||
wire.Struct(new(ServiceContainer), "*"),
|
||||
)
|
||||
|
||||
func InitializeContainer(cfg *config.MyConfig) *ServiceContainer {
|
||||
wire.Build(SuperSet)
|
||||
return &ServiceContainer{}
|
||||
}
|
||||
```
|
||||
|
||||
需要继续完成的重构步骤:
|
||||
|
||||
6. 替换所有具体类型引用为接口类型(示例):
|
||||
```go
|
||||
// data/coaster.go
|
||||
package data
|
||||
|
||||
import (
|
||||
"github.com/phyer/core/core"
|
||||
)
|
||||
|
||||
type CoasterRepo struct {
|
||||
candleManager core.CandleManager
|
||||
redisService core.RedisService
|
||||
}
|
||||
|
||||
func NewCoasterRepo(cm core.CandleManager, rs core.RedisService) *CoasterRepo {
|
||||
return &CoasterRepo{
|
||||
candleManager: cm,
|
||||
redisService: rs,
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
7. 添加Mock实现(示例):
|
||||
```go
|
||||
// core/mocks/segment_service_mock.go
|
||||
package mocks
|
||||
|
||||
import (
|
||||
"github.com/phyer/core/core"
|
||||
)
|
||||
|
||||
type MockSegmentService struct {
|
||||
core.SegmentService
|
||||
MockGetCurrentSegment func(period string) *core.CandleSegment
|
||||
}
|
||||
|
||||
func (m *MockSegmentService) GetCurrentSegment(period string) *core.CandleSegment {
|
||||
return m.MockGetCurrentSegment(period)
|
||||
}
|
||||
```
|
||||
|
||||
8. 统一异常处理规范:
|
||||
```go
|
||||
// core/error_handler.go
|
||||
func UnifiedRecovery() {
|
||||
if r := recover(); r != nil {
|
||||
err, ok := r.(error)
|
||||
if !ok {
|
||||
err = fmt.Errorf("panic: %v", r)
|
||||
}
|
||||
|
||||
stack := debug.Stack()
|
||||
appErr := NewAppError(err.Error(), 500).WithStack(string(stack))
|
||||
|
||||
handler := GetErrorHandler() // 从上下文中获取
|
||||
handler.HandleError(appErr, "global_recovery")
|
||||
}
|
||||
}
|
||||
|
||||
// 在关键入口使用
|
||||
func (cr *Core) SaveCandle(/*...*/) {
|
||||
defer UnifiedRecovery()
|
||||
// 业务逻辑...
|
||||
}
|
||||
```
|
||||
|
||||
建议后续采用以下步骤完成重构:
|
||||
|
||||
9. 创建`core/events.go`定义领域事件类型
|
||||
10. 在`data`层实现中添加事件发布点
|
||||
11. 使用wire等DI工具重构service初始化
|
||||
12. 为所有接口添加Mock实现
|
||||
13. 在关键流程添加统一度量指标
|
||||
14. 实现配置热加载机制
|
||||
|
||||
需要我继续展开哪部分的具体实现细节?
|
||||
|
||||
**Generation complete!** Please review the code suggestions above.
|
||||
68
量化交易相关/收益预估直方图.md
Normal file
68
量化交易相关/收益预估直方图.md
Normal file
@ -0,0 +1,68 @@
|
||||
|
||||
|
||||
```python
|
||||
import random
|
||||
import math
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
|
||||
# 初始本金
|
||||
initial_principal = 10000
|
||||
# 游戏次数
|
||||
num_games = 146
|
||||
# 获胜概率
|
||||
win_prob = 0.75
|
||||
# 年化赢利率
|
||||
annual_win_rate = 0.5
|
||||
# 年化输利率
|
||||
annual_loss_rate = -0.8
|
||||
# 模拟次数
|
||||
simulation_times = 10000
|
||||
|
||||
final_amounts = []
|
||||
|
||||
for _ in range(simulation_times):
|
||||
principal = initial_principal
|
||||
# 模拟游戏过程
|
||||
for _ in range(num_games):
|
||||
# 模拟游戏结果
|
||||
result = random.random()
|
||||
if result < win_prob:
|
||||
# 赢了
|
||||
daily_rate = (5 / 365) * annual_win_rate
|
||||
principal *= (1 + daily_rate)
|
||||
else:
|
||||
# 输了
|
||||
daily_rate = (5 / 365) * annual_loss_rate
|
||||
principal *= (1 + daily_rate)
|
||||
|
||||
final_amounts.append(principal)
|
||||
|
||||
# 绘制直方图
|
||||
plt.hist(final_amounts, bins=50, edgecolor='black')
|
||||
plt.title('Histogram of Final Amounts after 10000 Simulations')
|
||||
plt.xlabel('Final Amount')
|
||||
plt.ylabel('Frequency')
|
||||
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
### 代码解释
|
||||
|
||||
|
||||
|
||||
1. **模拟部分**:
|
||||
- 定义了初始本金、游戏次数、获胜概率、年化赢利率、年化输利率和模拟次数等参数。
|
||||
- 通过两层循环模拟一万次两年的游戏过程,每次游戏根据随机结果更新本金,并将每次模拟的最终资金存储在 `final_amounts` 列表中。
|
||||
2. **绘制直方图部分**:
|
||||
- 使用 `plt.hist()` 函数绘制 `final_amounts` 的直方图,`bins=50` 表示将数据分成 50 个区间,`edgecolor='black'` 为每个柱子添加黑色边框,使图形更清晰。
|
||||
- 使用 `plt.title()`、`plt.xlabel()` 和 `plt.ylabel()` 分别设置图形的标题、x 轴标签和 y 轴标签。
|
||||
3. **`plt.show()` 的作用**:
|
||||
- `plt.show()` 是 `matplotlib` 库中的一个函数,它的作用是显示当前绘制的图形。当你运行这段代码时,它会弹出一个窗口,在这个窗口中会显示绘制好的直方图图片。这个窗口允许你进行一些基本的操作,比如放大、缩小、保存图片等。
|
||||
|
||||
|
||||
|
||||
运行上述代码后,你会看到一个直方图,该直方图展示了一万次模拟后最终资金的分布情况,x 轴表示最终资金的数值区间,y 轴表示落在每个区间内的模拟次数(频率)。
|
||||
|
||||
![[Pasted image 20250222115616.png]]
|
||||
103
量化交易相关/更贝尔分布.md
Normal file
103
量化交易相关/更贝尔分布.md
Normal file
@ -0,0 +1,103 @@
|
||||
|
||||
在之前模拟游戏收益的情境中,模拟一万次后收益和实际年化利率的最高值、最低值本身并不一定对应着某种典型的已知函数形式。不过我们可以从以下几个角度来分析和探讨可能的关联:
|
||||
1. 数据分布特性与函数的关系
|
||||
模拟收益和年化利率的随机性
|
||||
每次模拟游戏的结果是随机的,由游戏的获胜概率、赢和输时的年化利率等因素共同决定。在多次模拟后,收益和年化利率的分布是基于大量随机事件的统计结果。
|
||||
这种随机性使得最高值和最低值的产生也是随机的,并不遵循简单的确定性函数规律。例如,每次模拟中游戏的输赢顺序不同,最终的收益和年化利率就会不同,从而导致最高值和最低值不断变化。
|
||||
2. 可能的近似分布及对应函数
|
||||
收益和年化利率的分布可能近似为某种概率分布
|
||||
正态分布:在某些情况下,如果模拟的次数足够多且满足一定条件,收益和年化利率可能近似服从正态分布。但最高值和最低值并非正态分布本身,而是从正态分布样本中选取的极端值。
|
||||
极值分布:对于大量随机变量的最大值和最小值,它们往往服从极值分布。常见的极值分布有三种类型:Gumbel 分布、Fréchet 分布和 Weibull 分布。
|
||||
Gumbel 分布:通常用于描述最大值的分布,当数据没有上限且分布的尾部较轻时,最大值可能服从 Gumbel 分布。
|
||||
Fréchet 分布:适用于具有重尾分布且没有上限的数据,最大值可能遵循此分布。
|
||||
Weibull 分布:可用于描述最小值的分布,当数据有下限且满足一定条件时,最小值可能服从 Weibull 分布。
|
||||
1. 通过代码验证近似分布
|
||||
以下是一个简单的示例,展示如何使用 Python 模拟游戏收益,并观察最高值和最低值的分布情况,尝试判断是否符合某种极值分布:
|
||||
|
||||
|
||||
```python
|
||||
import random
|
||||
import math
|
||||
import numpy as np
|
||||
import matplotlib.pyplot as plt
|
||||
from scipy.stats import gumbel_r, weibull_min
|
||||
|
||||
# 初始本金
|
||||
initial_principal = 10000
|
||||
# 游戏次数
|
||||
num_games = 146
|
||||
# 获胜概率
|
||||
win_prob = 0.75
|
||||
# 年化赢利率
|
||||
annual_win_rate = 0.5
|
||||
# 年化输利率
|
||||
annual_loss_rate = -0.8
|
||||
# 模拟次数
|
||||
simulation_times = 10000
|
||||
|
||||
final_amounts = []
|
||||
annual_interest_rates = []
|
||||
|
||||
for _ in range(simulation_times):
|
||||
principal = initial_principal
|
||||
# 模拟游戏过程
|
||||
for _ in range(num_games):
|
||||
# 模拟游戏结果
|
||||
result = random.random()
|
||||
if result < win_prob:
|
||||
# 赢了
|
||||
daily_rate = (5 / 365) * annual_win_rate
|
||||
principal *= (1 + daily_rate)
|
||||
else:
|
||||
# 输了
|
||||
daily_rate = (5 / 365) * annual_loss_rate
|
||||
principal *= (1 + daily_rate)
|
||||
|
||||
final_amounts.append(principal)
|
||||
# 计算实际年化利率
|
||||
years = 2
|
||||
annual_interest_rate = math.pow(principal / initial_principal, 1 / years) - 1
|
||||
annual_interest_rates.append(annual_interest_rate)
|
||||
|
||||
# 提取每次模拟中的最高和最低收益
|
||||
max_amounts = []
|
||||
min_amounts = []
|
||||
for i in range(0, simulation_times, 100): # 这里简单分组,每 100 次模拟一组
|
||||
group = final_amounts[i: i + 100]
|
||||
max_amounts.append(max(group))
|
||||
min_amounts.append(min(group))
|
||||
|
||||
# 绘制最高值的直方图并拟合 Gumbel 分布
|
||||
plt.figure(figsize=(12, 6))
|
||||
plt.subplot(1, 2, 1)
|
||||
plt.hist(max_amounts, bins=30, density=True, alpha=0.6, color='g')
|
||||
params = gumbel_r.fit(max_amounts)
|
||||
x = np.linspace(min(max_amounts), max(max_amounts), 100)
|
||||
plt.plot(x, gumbel_r.pdf(x, *params), 'r-', lw=2)
|
||||
plt.title('Distribution of Max Amounts (Fitted Gumbel)')
|
||||
|
||||
# 绘制最低值的直方图并拟合 Weibull 分布
|
||||
plt.subplot(1, 2, 2)
|
||||
plt.hist(min_amounts, bins=30, density=True, alpha=0.6, color='b')
|
||||
params = weibull_min.fit(min_amounts)
|
||||
x = np.linspace(min(min_amounts), max(min_amounts), 100)
|
||||
plt.plot(x, weibull_min.pdf(x, *params), 'r-', lw=2)
|
||||
plt.title('Distribution of Min Amounts (Fitted Weibull)')
|
||||
|
||||
plt.show()
|
||||
```
|
||||
|
||||
|
||||
![[Pasted image 20250222113205.png]]
|
||||
|
||||
这张图包含两个子图,分别展示了模拟游戏收益中最高值和最低值的分布情况,以及它们与特定极值分布的拟合结果:
|
||||
|
||||
### 左图:Distribution of Max Amounts (Fitted Gumbel)
|
||||
- **直方图**:绿色的直方图表示每次分组模拟(每100次模拟为一组)中的最高收益的分布频率。纵轴是概率密度,横轴是收益金额。可以看到,收益最高值主要集中在一定范围内,其中某个区间的出现频率相对较高,而两端的频率较低。
|
||||
- **红色曲线**:这条曲线是根据Gumbel分布拟合得到的概率密度函数(PDF)。通过将模拟数据拟合到Gumbel分布,我们可以判断最高收益的分布是否近似符合Gumbel分布。从图中可以看出,红色曲线与直方图的形状有一定的契合度,说明最高收益的分布在一定程度上符合Gumbel分布的特征。
|
||||
|
||||
### 右图:Distribution of Min Amounts (Fitted Weibull)
|
||||
- **直方图**:蓝色的直方图展示了每次分组模拟中的最低收益的分布频率。同样,纵轴是概率密度,横轴是收益金额。最低收益值的分布也呈现出一定的集中趋势,有一个出现频率较高的区间。
|
||||
- **红色曲线**:该曲线是根据Weibull分布拟合得到的概率密度函数(PDF)。将模拟数据拟合到Weibull分布,以判断最低收益的分布是否符合Weibull分布。从图中可见,红色曲线与直方图的形状也较为匹配,表明最低收益的分布在一定程度上符合Weibull分布的特点。
|
||||
|
||||
总体而言,通过直方图和拟合曲线的对比,可以初步判断在这个游戏收益模拟中,最高收益的分布近似符合Gumbel分布,最低收益的分布近似符合Weibull分布。
|
||||
1817
量化交易系统建议.md
Normal file
1817
量化交易系统建议.md
Normal file
File diff suppressed because it is too large
Load Diff
69
随便/开车时听的音乐.md
Normal file
69
随便/开车时听的音乐.md
Normal file
@ -0,0 +1,69 @@
|
||||
|
||||
开车时听音乐是个很棒的选择,既能放松心情,又能保持专注。我会推荐一些适合开车时听的单曲和专辑,涵盖不同风格,既有轻松的节奏,也有振奋人心的旋律,适合长途或短途驾驶:
|
||||
|
||||
单曲推荐
|
||||
|
||||
1. "Sweet Home Alabama" - Lynyrd Skynyrd
|
||||
甜蜜的阿拉巴马 - Lynyrd Skynyrd
|
||||
|
||||
- 经典南方摇滚,节奏明快,旋律朗朗上口,非常适合在公路上播放。
|
||||
|
||||
2. "Take It Easy" - Eagles
|
||||
"放松一下" - 鹰乐队
|
||||
|
||||
- 这首歌轻松惬意,尤其是那句“Well, I’m a-standin’ on a corner in Winslow, Arizona”,仿佛是为开车而生。
|
||||
|
||||
3. "Blinding Lights" - The Weeknd
|
||||
"闪耀之光" - The Weeknd
|
||||
|
||||
- 带有80年代复古电子风,节奏感强,适合夜间驾驶提神。
|
||||
|
||||
4. "Don’t Stop Me Now" - Queen
|
||||
不要停止我,现在 - 皇后乐队
|
||||
|
||||
- 充满能量的一首歌,Freddie Mercury的嗓音会让你感觉像在飞驰。
|
||||
|
||||
5. "Smooth" - Santana feat. Rob Thomas
|
||||
平滑 - 桑塔纳 feat. 罗布·托马斯
|
||||
|
||||
- 拉丁摇滚的律动,既放松又有活力,非常适合悠闲的旅程。
|
||||
|
||||
|
||||
专辑推荐
|
||||
|
||||
1. 《Rumours》 - Fleetwood Mac (1977)
|
||||
《谣言》 - 森林乐队 (1977)
|
||||
|
||||
- 这张专辑旋律优美,情绪丰富,像“Go Your Own Way”和“Dreams”这样的曲子特别适合在路上听。
|
||||
|
||||
2. 《The Joshua Tree》 - U2 (1987)
|
||||
《 Joshua Tree》 - U2 (1987)
|
||||
|
||||
- 充满史诗感的摇滚专辑,尤其是“Where the Streets Have No Name”,让人感觉像在开阔的荒野中飞驰。
|
||||
|
||||
3. 《Random Access Memories》 - Daft Punk (2013)
|
||||
《随机存取回忆》 - Daft Punk (2013)
|
||||
|
||||
- 电子与放克的完美结合,“Get Lucky”和“Instant Crush”节奏感强又不失轻松。
|
||||
|
||||
4. 《Born to Run》 - Bruce Springsteen (1975)
|
||||
《生来就跑》 - 布鲁斯·斯普林斯汀 (1975)
|
||||
|
||||
- 这张专辑充满了对自由和公路的渴望,尤其是标题曲“Born to Run”,简直是驾驶者的 anthem。
|
||||
|
||||
5. 《Chillhop Essentials》 - Various Artists
|
||||
《Chillhop 必备曲目》 - 多位艺术家
|
||||
|
||||
- 如果你喜欢更轻松的背景音乐,这个系列的 lo-fi hip-hop 非常适合长途驾驶,既放松又不会让人分心。
|
||||
|
||||
|
||||
小建议
|
||||
|
||||
- 长途驾驶:选择节奏平稳、旋律舒缓的音乐,比如 Fleetwood Mac 或 lo-fi,避免太激烈的曲风让你疲劳。
|
||||
|
||||
- 城市驾驶:可以挑一些节奏感强的,比如 The Weeknd 或 Santana,保持警觉。
|
||||
|
||||
- 夜间驾驶:带点电子风或振奋人心的歌,像 Queen 或 Daft Punk,能帮你提神。
|
||||
|
||||
|
||||
你平时喜欢哪种风格的音乐?我可以根据你的喜好再调整推荐!
|
||||
494
随便/甘特图流程图各种图.md
Normal file
494
随便/甘特图流程图各种图.md
Normal file
@ -0,0 +1,494 @@
|
||||
|
||||
|
||||
https://support.typora.io/Draw-Diagrams-With-Markdown/#sequence-diagrams-1
|
||||
|
||||
|
||||
- [Back](https://support.typora.io/)
|
||||
|
||||
# Draw Diagrams With Markdown
|
||||
|
||||
September 5, 2022 by typora.io
|
||||
|
||||
- [Precondition](https://support.typora.io/Draw-Diagrams-With-Markdown/#precondition)
|
||||
- [Sequence Diagrams](https://support.typora.io/Draw-Diagrams-With-Markdown/#sequence-diagrams)
|
||||
- [Sequence Diagrams Options](https://support.typora.io/Draw-Diagrams-With-Markdown/#sequence-diagrams-options)
|
||||
- [Flowcharts](https://support.typora.io/Draw-Diagrams-With-Markdown/#flowcharts)
|
||||
- [Mermaid](https://support.typora.io/Draw-Diagrams-With-Markdown/#mermaid)
|
||||
- [Sequence Diagrams](https://support.typora.io/Draw-Diagrams-With-Markdown/#sequence-diagrams-1)
|
||||
- [Flowcharts](https://support.typora.io/Draw-Diagrams-With-Markdown/#flowcharts-1)
|
||||
- [Gantt Charts](https://support.typora.io/Draw-Diagrams-With-Markdown/#gantt-charts)
|
||||
- [Class Diagrams](https://support.typora.io/Draw-Diagrams-With-Markdown/#class-diagrams)
|
||||
- [State Diagrams](https://support.typora.io/Draw-Diagrams-With-Markdown/#state-diagrams)
|
||||
- [Pie Charts](https://support.typora.io/Draw-Diagrams-With-Markdown/#pie-charts)
|
||||
- [Requirement Diagram](https://support.typora.io/Draw-Diagrams-With-Markdown/#requirement-diagram)
|
||||
- [Gitgraph Diagrams / Commit Flow](https://support.typora.io/Draw-Diagrams-With-Markdown/#gitgraph-diagrams--commit-flow)
|
||||
- [C4 Diagrams (plantUML compatible)](https://support.typora.io/Draw-Diagrams-With-Markdown/#c4-diagrams-plantuml-compatible)
|
||||
- [Mindmap](https://support.typora.io/Draw-Diagrams-With-Markdown/#mindmap)
|
||||
- [Timeline](https://support.typora.io/Draw-Diagrams-With-Markdown/#timeline)
|
||||
- [Quadrant Chart](https://support.typora.io/Draw-Diagrams-With-Markdown/#quadrant-chart)
|
||||
- [Sankey diagrams](https://support.typora.io/Draw-Diagrams-With-Markdown/#sankey-diagrams)
|
||||
- [ZenUML](https://support.typora.io/Draw-Diagrams-With-Markdown/#zenuml)
|
||||
- [XY Chart](https://support.typora.io/Draw-Diagrams-With-Markdown/#xy-chart)
|
||||
- [Global Mermaid Options](https://support.typora.io/Draw-Diagrams-With-Markdown/#global-mermaid-options)
|
||||
- [Overview](https://support.typora.io/Draw-Diagrams-With-Markdown/#overview)
|
||||
- [Diagram Alignment](https://support.typora.io/Draw-Diagrams-With-Markdown/#diagram-alignment)
|
||||
- [Mermaid Theme](https://support.typora.io/Draw-Diagrams-With-Markdown/#mermaid-theme)
|
||||
- [Auto Numbering](https://support.typora.io/Draw-Diagrams-With-Markdown/#auto-numbering)
|
||||
- [Flowchart Curve](https://support.typora.io/Draw-Diagrams-With-Markdown/#flowchart-curve)
|
||||
- [Gantt Padding](https://support.typora.io/Draw-Diagrams-With-Markdown/#gantt-padding)
|
||||
- [Inline Mermaid Config](https://support.typora.io/Draw-Diagrams-With-Markdown/#inline-mermaid-config)
|
||||
- [Save-as / Copy on Diagrams](https://support.typora.io/Draw-Diagrams-With-Markdown/#save-as--copy-on-diagrams)
|
||||
|
||||
# Precondition
|
||||
|
||||
Typora supports some Markdown extensions for diagrams, to use this feature, first **please enable Diagrams in Preferences Panel → Markdown section**.
|
||||
|
||||
When exporting as HTML, PDF, epub or docx, those rendered diagrams will also be included, but diagram features are not supported when exporting Markdown into other file formats in the current version. Also, you should note that diagrams are not supported by standard Markdown, CommonMark or GFM. Therefore, we still recommend you to insert an image of these diagrams instead of writing them in Markdown directly.
|
||||
|
||||
# Sequence Diagrams
|
||||
|
||||
This feature uses [js-sequence](https://bramp.github.io/js-sequence-diagrams/), which turns the following code block into a rendered diagram:
|
||||
|
||||
````gfm
|
||||
```sequence
|
||||
Alice->Bob: Hello Bob, how are you?
|
||||
Note right of Bob: Bob thinks
|
||||
Bob-->Alice: I am good thanks!
|
||||
```
|
||||
````
|
||||
|
||||
|
||||
|
||||
For more details, please see [this syntax explanation](https://bramp.github.io/js-sequence-diagrams/#syntax).
|
||||
|
||||
### Sequence Diagrams Options
|
||||
|
||||
You can change the CSS variable `--sequence-theme` to set the theme for sequence diagrams, supported values are `simple` (default) and `hand`. For example, add the following CSS in [Custom CSS](https://support.typora.io/Add-Custom-CSS/), and you will get:
|
||||
|
||||
```
|
||||
:root {
|
||||
--sequence-theme: hand
|
||||
}
|
||||
```
|
||||
|
||||
|–sequence-theme: simple|–sequence-theme: hand|
|
||||
|---|---|
|
||||
|||
|
||||
|
||||
# Flowcharts
|
||||
|
||||
This feature uses [flowchart.js](http://flowchart.js.org/), which turns the following code block into a rendered diagram:
|
||||
|
||||
````gfm
|
||||
```flow
|
||||
st=>start: Start
|
||||
op=>operation: Your Operation
|
||||
cond=>condition: Yes or No?
|
||||
e=>end
|
||||
|
||||
st->op->cond
|
||||
cond(yes)->e
|
||||
cond(no)->op
|
||||
```
|
||||
````
|
||||
|
||||
```flow
|
||||
st=>start: Start
|
||||
op=>operation: Your Operation
|
||||
cond=>condition: Yes or No?
|
||||
e=>end
|
||||
|
||||
st->op->cond
|
||||
cond(yes)->e
|
||||
cond(no)->op
|
||||
```
|
||||
|
||||
|
||||
# Mermaid
|
||||
|
||||
Typora also has integration with [mermaid](https://mermaid-js.github.io/mermaid/#/), which supports sequence diagrams, flowcharts, Gantt charts, class and state diagrams, and pie charts.
|
||||
|
||||
## Sequence Diagrams
|
||||
|
||||
For more details see [these instructions](https://mermaid.js.org/syntax/sequenceDiagram.html).
|
||||
|
||||
````gfm
|
||||
|
||||
````
|
||||
|
||||
|
||||
```mermaid
|
||||
%% Example of sequence diagram
|
||||
sequenceDiagram
|
||||
Alice->>Bob: Hello Bob, how are you?
|
||||
alt is sick
|
||||
Bob->>Alice: Not so good :(
|
||||
else is well
|
||||
Bob->>Alice: Feeling fresh like a daisy
|
||||
end
|
||||
opt Extra response
|
||||
Bob->>Alice: Thanks for asking
|
||||
end
|
||||
```
|
||||
## Flowcharts
|
||||
|
||||
For more details see [these instructions](https://mermaid.js.org/syntax/flowchart.html).
|
||||
|
||||
````gfm
|
||||
```mermaid
|
||||
graph LR
|
||||
A[Hard edge] -->B(Round edge)
|
||||
B --> C{Decision}
|
||||
C -->|One| D[Result one]
|
||||
C -->|Two| E[Result two]
|
||||
```
|
||||
````
|
||||
|
||||
|
||||
```mermaid
|
||||
graph LR
|
||||
A[Hard edge] -->B(Round edge)
|
||||
B --> C{Decision}
|
||||
C -->|One| D[Result one]
|
||||
C -->|Two| E[Result two]
|
||||
```
|
||||
## Gantt Charts
|
||||
|
||||
For more details see [these instructions](https://mermaid.js.org/syntax/gantt.html).
|
||||
|
||||
````gfm
|
||||
```mermaid
|
||||
%% Example with selection of syntaxes
|
||||
gantt
|
||||
dateFormat YYYY-MM-DD
|
||||
title Adding GANTT diagram functionality to mermaid
|
||||
|
||||
section A section
|
||||
Completed task :done, des1, 2014-01-06,2014-01-08
|
||||
Active task :active, des2, 2014-01-09, 3d
|
||||
Future task : des3, after des2, 5d
|
||||
Future task2 : des4, after des3, 5d
|
||||
|
||||
section Critical tasks
|
||||
Completed task in the critical line :crit, done, 2014-01-06,24h
|
||||
Implement parser and jison :crit, done, after des1, 2d
|
||||
Create tests for parser :crit, active, 3d
|
||||
Future task in critical line :crit, 5d
|
||||
Create tests for renderer :2d
|
||||
Add to mermaid :1d
|
||||
|
||||
section Documentation
|
||||
Describe gantt syntax :active, a1, after des1, 3d
|
||||
Add gantt diagram to demo page :after a1 , 20h
|
||||
Add another diagram to demo page :doc1, after a1 , 48h
|
||||
|
||||
section Last section
|
||||
Describe gantt syntax :after doc1, 3d
|
||||
Add gantt diagram to demo page : 20h
|
||||
Add another diagram to demo page : 48h
|
||||
```
|
||||
````
|
||||
|
||||
|
||||
|
||||
```mermaid
|
||||
%% Example with selection of syntaxes
|
||||
gantt
|
||||
dateFormat YYYY-MM-DD
|
||||
title Adding GANTT diagram functionality to mermaid
|
||||
|
||||
section A section
|
||||
Completed task :done, des1, 2014-01-06,2014-01-08
|
||||
Active task :active, des2, 2014-01-09, 3d
|
||||
Future task : des3, after des2, 5d
|
||||
Future task2 : des4, after des3, 5d
|
||||
|
||||
section Critical tasks
|
||||
Completed task in the critical line :crit, done, 2014-01-06,24h
|
||||
Implement parser and jison :crit, done, after des1, 2d
|
||||
Create tests for parser :crit, active, 3d
|
||||
Future task in critical line :crit, 5d
|
||||
Create tests for renderer :2d
|
||||
Add to mermaid :1d
|
||||
|
||||
section Documentation
|
||||
Describe gantt syntax :active, a1, after des1, 3d
|
||||
Add gantt diagram to demo page :after a1 , 20h
|
||||
Add another diagram to demo page :doc1, after a1 , 48h
|
||||
|
||||
section Last section
|
||||
Describe gantt syntax :after doc1, 3d
|
||||
Add gantt diagram to demo page : 20h
|
||||
Add another diagram to demo page : 48h
|
||||
```
|
||||
|
||||
## Class Diagrams
|
||||
|
||||
For more details see [these instructions](https://mermaid.js.org/syntax/classDiagram.html).
|
||||
|
||||
````gfm
|
||||
```mermaid
|
||||
classDiagram
|
||||
Animal <|-- Duck
|
||||
Animal <|-- Fish
|
||||
Animal <|-- Zebra
|
||||
Animal : +int age
|
||||
Animal : +String gender
|
||||
Animal: +isMammal()
|
||||
Animal: +mate()
|
||||
class Duck{
|
||||
+String beakColor
|
||||
+swim()
|
||||
+quack()
|
||||
}
|
||||
class Fish{
|
||||
-int sizeInFeet
|
||||
-canEat()
|
||||
}
|
||||
class Zebra{
|
||||
+bool is_wild
|
||||
+run()
|
||||
}
|
||||
```
|
||||
````
|
||||
|
||||
|
||||
|
||||
## State Diagrams
|
||||
|
||||
For more details see [these instructions](https://mermaid.js.org/syntax/stateDiagram.html).
|
||||
```mermaid
|
||||
stateDiagram
|
||||
[*] --> Still
|
||||
Still --> [*]
|
||||
|
||||
Still --> Moving
|
||||
Moving --> Still
|
||||
Moving --> Crash
|
||||
Crash --> [*]
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Pie Charts
|
||||
|
||||
```mermaid
|
||||
pie
|
||||
title Pie Chart
|
||||
"Dogs" : 386
|
||||
"Cats" : 85
|
||||
"Rats" : 150
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Requirement Diagram
|
||||
|
||||
A Requirement diagram provides a visualization for requirements and their connections, to each other and other documented elements. The modeling specs follow those defined by SysML v1.6.
|
||||
|
||||
You can find details [here](https://mermaid-js.github.io/mermaid/#/requirementDiagram).
|
||||
|
||||
```mermaid
|
||||
requirementDiagram
|
||||
|
||||
requirement test_req {
|
||||
id: 1
|
||||
text: the test text.
|
||||
risk: high
|
||||
verifymethod: test
|
||||
}
|
||||
|
||||
element test_entity {
|
||||
type: simulation
|
||||
}
|
||||
|
||||
test_entity - satisfies -> test_req
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Gitgraph Diagrams / Commit Flow
|
||||
|
||||
A Git Graph is a pictorial representation of git commits and git actions(commands) on various branches.
|
||||
|
||||
You can find details [here](https://mermaid.js.org/syntax/gitgraph.html).
|
||||
|
||||
```mermaid
|
||||
gitGraph
|
||||
commit
|
||||
commit
|
||||
branch develop
|
||||
checkout develop
|
||||
commit
|
||||
commit
|
||||
checkout main
|
||||
merge develop
|
||||
commit
|
||||
commit
|
||||
```
|
||||
|
||||
|
||||
|
||||
## C4 Diagrams (plantUML compatible)
|
||||
|
||||
Mermaid’s c4 diagram syntax is compatible with plantUML.
|
||||
|
||||
You can find details [here](https://mermaid.js.org/syntax/c4c.html).
|
||||
|
||||
## Mindmap
|
||||
|
||||
A mind map is a diagram used to visually organize information into a hierarchy, showing relationships among pieces of the whole. It is often created around a single concept, drawn as an image in the center of a blank page, to which associated representations of ideas such as images, words and parts of words are added. Major ideas are connected directly to the central concept, and other ideas branch out from those major ideas.
|
||||
|
||||
You can find details [here](https://mermaid.js.org/syntax/mindmap.html).
|
||||
|
||||
````gfm
|
||||
```mermaid
|
||||
mindmap
|
||||
root((mindmap))
|
||||
Origins
|
||||
Long history
|
||||
::icon(fa fa-book)
|
||||
Popularisation
|
||||
British popular psychology author Tony Buzan
|
||||
Research
|
||||
On effectiveness<br/>and features
|
||||
On Automatic creation
|
||||
Uses
|
||||
Creative techniques
|
||||
Strategic planning
|
||||
Argument mapping
|
||||
Tools
|
||||
Pen and paper
|
||||
Mermaid
|
||||
```
|
||||
````
|
||||
|
||||
```mermaid
|
||||
mindmap
|
||||
root((mindmap))
|
||||
Origins
|
||||
Long history
|
||||
::icon(fa fa-book)
|
||||
Popularisation
|
||||
British popular psychology author Tony Buzan
|
||||
Research
|
||||
On effectiveness<br/>and features
|
||||
On Automatic creation
|
||||
Uses
|
||||
Creative techniques
|
||||
Strategic planning
|
||||
Argument mapping
|
||||
Tools
|
||||
Pen and paper
|
||||
Mermaid
|
||||
```
|
||||
|
||||

|
||||
|
||||
## Timeline
|
||||
|
||||
See [https://mermaid.js.org/syntax/timeline.html](https://mermaid.js.org/syntax/timeline.html) for detail.
|
||||
|
||||
|
||||
|
||||
## Quadrant Chart
|
||||
|
||||
See [https://mermaid.js.org/syntax/quadrantChart.html](https://mermaid.js.org/syntax/quadrantChart.html) for details.
|
||||
|
||||
|
||||
|
||||
## Sankey diagrams
|
||||
|
||||
See [https://mermaid.js.org/syntax/sankey.html](https://mermaid.js.org/syntax/sankey.html) for details.
|
||||
|
||||
|
||||
|
||||
## ZenUML
|
||||
|
||||
See [https://mermaid.js.org/syntax/zenuml.html](https://mermaid.js.org/syntax/zenuml.html) for details.
|
||||
|
||||
|
||||
|
||||
Please notice that zenuml is not first class diagram in mermaid, it may lack some features, like dark themes, etc.
|
||||
|
||||
## XY Chart
|
||||
|
||||
You can find more details here → https://mermaid.js.org/syntax/xyChart.html.
|
||||
|
||||
You can now draw charts like this:
|
||||
|
||||
|
||||
|
||||
## Global Mermaid Options
|
||||
|
||||
### Overview
|
||||
|
||||
You can change Mermaid options by adding [Custom CSS](https://support.typora.io/Add-Custom-CSS/), supported options include:
|
||||
|
||||
```
|
||||
:root {
|
||||
--mermaid-theme: default; /*or base, dark, forest, neutral, night */
|
||||
--mermaid-font-family: "trebuchet ms", verdana, arial, sans-serif;
|
||||
--mermaid-sequence-numbers: off; /* or "on", see https://mermaid-js.github.io/mermaid/#/sequenceDiagram?id=sequencenumbers*/
|
||||
--mermaid-flowchart-curve: linear /* or "basis", see https://github.com/typora/typora-issues/issues/1632*/;
|
||||
--mermaid--gantt-left-padding: 75; /* see https://github.com/typora/typora-issues/issues/1665*/
|
||||
}
|
||||
```
|
||||
|
||||
Please note that if you export a document with themes other than the currently used one, some mermaid options will not be applied to exported HTML / PDF / Images. For example, if you currently use the Github theme, then export to PDF using the theme YYY and YYY.css defines `--mermaid-sequence-numbers: on`, then the `--mermaid-sequence-numbers: on` would not be applied to the exported PDF.
|
||||
|
||||
### Diagram Alignment
|
||||
|
||||
You can add the custom CSS below by following [Add Custom CSS](https://support.typora.io/Add-Custom-CSS/) to left align your diagram.
|
||||
|
||||
```
|
||||
.md-diagram-panel-preview {text-align:left;}
|
||||
```
|
||||
|
||||
### Mermaid Theme
|
||||
|
||||
The `--mermaid-theme` css variable can quickly define a mermaid theme that fits your theme, the value can be `base`, `default`, `dark`, `forest`, `neutral` or `night` (the one used in night theme), for example:
|
||||
|
||||
|CSS|Mermaid Demo|
|
||||
|---|---|
|
||||
|`:root {--mermaid-theme:dark;}`||
|
||||
|`:root {--mermaid-theme:neutral;}`||
|
||||
|`:root {--mermaid-theme:forest;}`||
|
||||
|
||||
### Auto Numbering
|
||||
|
||||
Adding `--mermaid-sequence-numbers: on;` in the [Custom CSS](https://support.typora.io/Add-Custom-CSS/) will enable auto numbering for sequences in mermaid:
|
||||
|
||||
|–mermaid-sequence-numbers:off|–mermaid-sequence-numbers:on|
|
||||
|---|---|
|
||||
|||
|
||||
|
||||
### Flowchart Curve
|
||||
|
||||
Add `--mermaid-flowchart-curve: basis` to get other type of curves.
|
||||
|
||||
|–mermaid-flowchart-curve: linear;|–mermaid-flowchart-curve: basis|–mermaid-flowchart-curve: natural;|–mermaid-flowchart-curve: step;|
|
||||
|---|---|---|---|
|
||||
|||||
|
||||
|
||||
### Gantt Padding
|
||||
|
||||
|–mermaid–gantt-left-padding:75|–mermaid–gantt-left-padding:200|
|
||||
|---|---|
|
||||
|||
|
||||
|
||||
## Inline Mermaid Config
|
||||
|
||||
You can add `%%{init: [options]}%%` to the first line of your mermaid diagram to configure mermaid details as shown below:
|
||||
|
||||
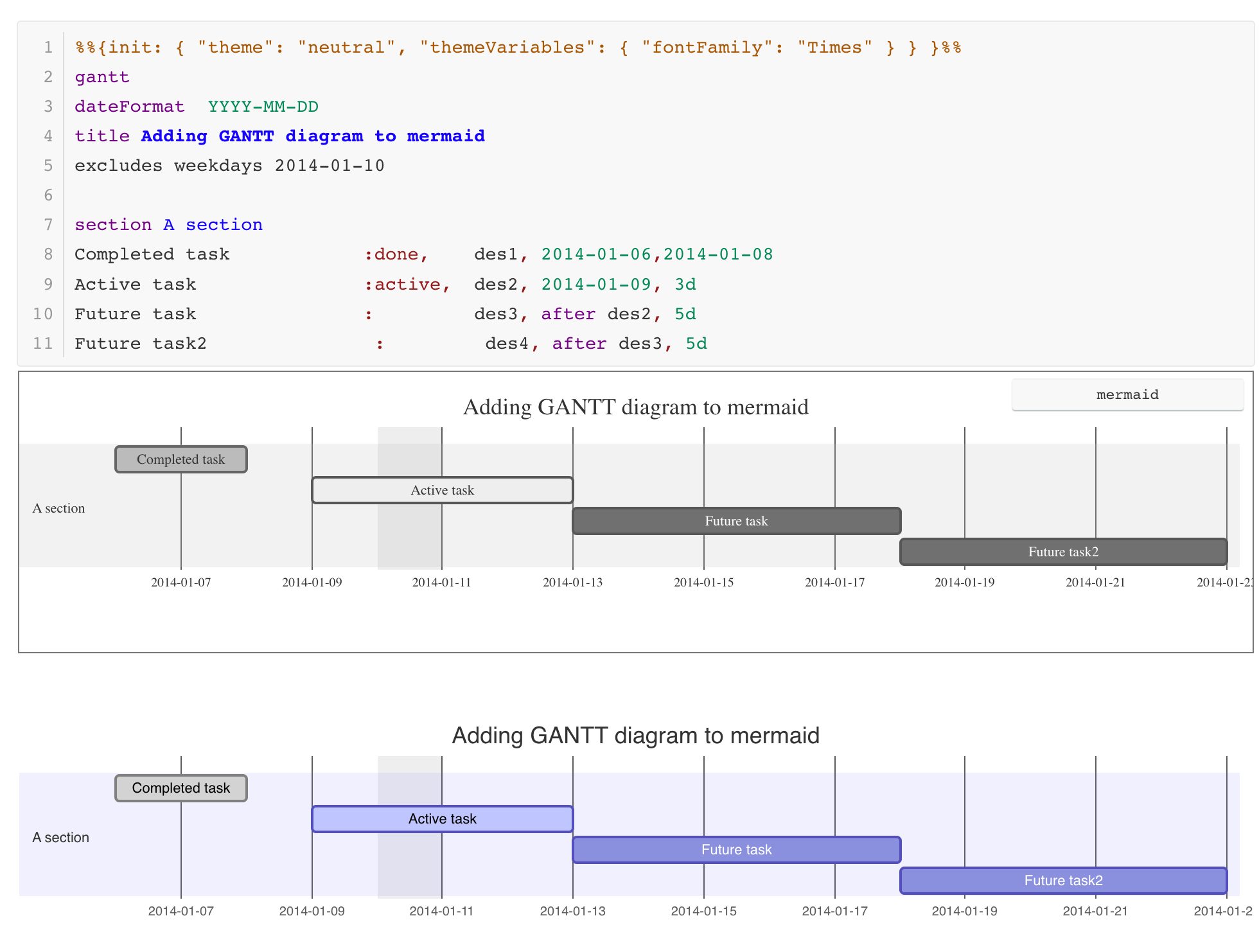
|
||||
|
||||
You can find full documentation at [https://mermaid-js.github.io/mermaid/#/./directives](https://mermaid-js.github.io/mermaid/#/./directives).
|
||||
|
||||
# Save-as / Copy on Diagrams
|
||||
|
||||
You can right click on a diagram to save it as a SVG, PNG or JPG file on your local disk.
|
||||
|
||||
Also, you can right click on a diagram to copy it to your clipboard.
|
||||
|
||||
[Get Typora](https://store.typora.io) / [Help Improve our documents](https://github.com/typora/wiki-website)
|
||||
Loading…
x
Reference in New Issue
Block a user